
Los sistemas de gestión de bases de datos relacionales (RDBMS) como PostgreSQL y MySQL son fundamentales para almacenar, organizar y acceder a datos para aplicaciones y análisis. PostgreSQL y MySQL son populares bases de datos de código abierto con largas historias y conjuntos de funciones completos.
[glossary_term_es title=”Base de Datos” text=”Una base de datos es una colección de información que está accesible para las computadoras. Las bases de datos se usan para almacenar información como los registros de los clientes, los catálogos de productos y las transacciones financieras.”]
Sin embargo, PostgreSQL y MySQL difieren en sus arquitecturas técnicas y filosofía de diseño. Si te encuentras en la encrucijada de elegir una base de datos para tu aplicación, esta guía es para ti.
Exploramos las diferencias técnicas, prácticas y estratégicas entre PostgreSQL y MySQL. ¡Comencemos!
Un Historial Breve Sobre PostgreSQL y MySQL
Antes de adentrarnos en las comparaciones, permítenos presentarte brevemente a PostgreSQL y MySQL.
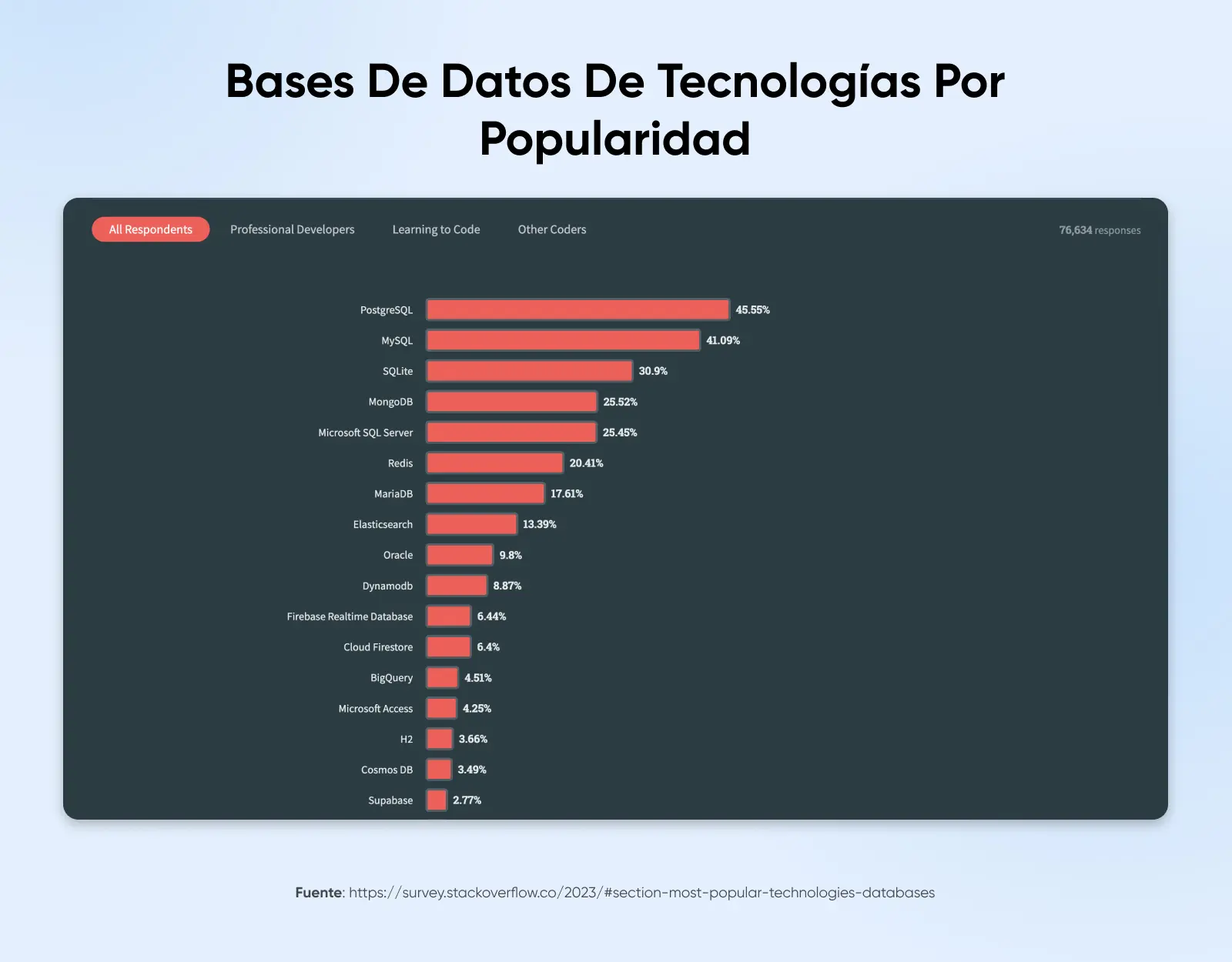
PostgreSQL es una base de datos relacional de código abierto de nivel empresarial. Utilizada por más del 45% de los 76,000 encuestados en la reciente encuesta de desarrolladores de StackOverflow, PostgreSQL superó a MySQL para convertirse en la base de datos más popular en 2024.
PostgreSQL enfatiza la conformidad con los estándares, la capacidad de extensión y las arquitecturas probadas. El proyecto PostgreSQL comenzó en 1986 en la Universidad de California, Berkeley, y ha desarrollado características centradas en la confiabilidad, robustez, integridad de datos y corrección.
Postgres emplea un sistema de cinco niveles:
- Instancia (también llamada clúster)
- Base de datos
- Esquema
- Tabla
- Columna
Aquí tienes un ejemplo de cómo crear una tabla de usuarios simple en PostgreSQL e insertar algunas filas:
CREATE TABLE users ( user_id SERIAL PRIMARY KEY, name VARCHAR(50), email VARCHAR(100) ); INSERT INTO users (name, email) VALUES ('John Doe', 'john@email.com'), ('Jane Smith', 'jane@email.com'); |
MySQL es un sistema de gestión de bases de datos relacionales (RDBMS) de código abierto iniciado por la compañía sueca MySQL AB en 1995, la cual más tarde fue adquirida por Oracle. Tradicionalmente, ha priorizado la velocidad, la simplicidad y la facilidad de uso para desarrollar aplicaciones web y embebidas. El diseño de MySQL enfatiza un rendimiento rápido en lectura y escritura.
MySQL emplea un sistema de cuatro niveles:
- Instancia
- Base de datos
- Tabla
- Columna
Aquí tienes cómo puedes crear la tabla de usuarios en MySQL:
CREATE TABLE users ( user_id INT AUTO_INCREMENT PRIMARY KEY, name VARCHAR(50), email VARCHAR(100) ); INSERT INTO users (name, email) VALUES ('John Doe', 'john@email.com'), ('Jane Smith', 'jane@email.com'); |
Como puedes notar, ambas consultas son similares, excepto por el cambio de INT AUTO_INCREMENT a SERIAL.
Dato curioso: PostgreSQL soporta la palabra clave “allballs” de la NASA (que significa “todos ceros”) como otra forma de expresar la hora de medianoche (local y UTC):
postgres=# SELECT 'allballs'::TIME; time ---------- 00:00:00 (1 row) |
Entonces, ¿cómo se comparan estos dos gigantes de las bases de datos de código abierto? Vamos a explorar más a fondo.
Comparación de Rendimiento Entre PostgreSQL y MySQL
Tanto PostgreSQL como MySQL son capaces de un excelente rendimiento, pero no hay un claro ganador entre ellos.
Si pruebas la velocidad de lectura/escritura, notarás que no hay una consistencia en cómo PostgreSQL y MySQL se desempeñan. Esto se debe a que el rendimiento de la base de datos depende en gran medida de tu tipo de carga de trabajo específica, configuración de hardware, esquema y índices de base de datos, y especialmente de la configuración de ajuste de la base de datos. Esencialmente, el rendimiento depende en gran medida de la carga de trabajo y las configuraciones de tu aplicación.
Hay cinco categorías generales de cargas de trabajo:
- CRUD: Operaciones simples de LEER, ESCRIBIR, ACTUALIZAR y ELIMINAR.
- OLTP: Operaciones transaccionales, complejas de procesamiento de datos.
- OLAP: Procesos de lotes analíticos.
- HTAP: Procesamiento híbrido de transacciones y análisis.
- Time-Series: Datos de series de tiempo con patrones de acceso muy simples, pero de alta frecuencia.
Cuando trabajas con cualquiera de estos flujos de trabajo, observarás que:

PostgreSQL es conocido por manejar eficientemente cargas de trabajo OLAP y OLTP pesadas. Estas cargas de trabajo involucran consultas extremadamente complejas y de larga duración que analizan conjuntos de datos masivos, por ejemplo, consultas de inteligencia empresarial o análisis geo espacial.
““Postgres me permite ver una estimación del plan “antes de que se ejecute” la consulta, así como un plan “después de la ejecución”. Este último me proporciona información detallada sobre cómo se ejecutó realmente la consulta, cuánto tiempo tomó cada paso específico en la consulta, los índices utilizados y cuánta memoria consumió cada paso.”
MySQL es generalmente bueno para cargas de trabajo CRUD y OLTP más simples que involucran lecturas y escrituras más rápidas, como aplicaciones web o móviles.
Ambas bases de datos pueden destacarse dependiendo de la configuración del servidor y tu esquema para cargas de trabajo híbridas con una combinación de consultas OLTP y OLAP.
[glossary_term_es title=”Query” text=”En las bases de datos, las consultas son solicitudes de conjuntos específicos de información. Las consultas también pueden ser preguntas abiertas para datos que coincidan con los parámetros que establezcas.”]
Cuando se trata de potencia bruta en hardware optimizado, PostgreSQL generalmente escala mejor para usar la memoria alta, procesadores más rápidos y más núcleos disponibles en el hardware.
Rendimiento de Lectura
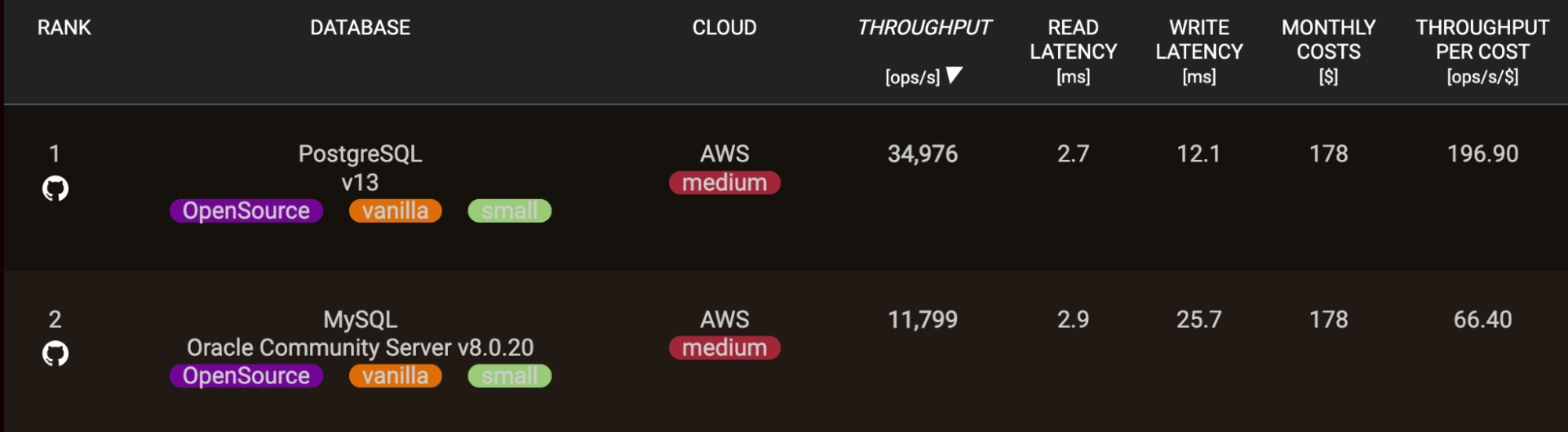
MySQL generalmente tiene tiempos de lectura más rápidos para aplicaciones que para operaciones de escritura. Sin embargo, después de las actualizaciones recientes en PostgreSQL, ha alcanzado las diferencias de velocidad de lectura.
Esta ventaja en el rendimiento de lectura se deriva de las diferencias en la arquitectura de los dos sistemas: los motores de almacenamiento de MySQL están altamente optimizados para un rápido acceso secuencial de un solo hilo.
Por supuesto, con ajustes y esquemas personalizados, PostgreSQL también puede ofrecer un excelente rendimiento de lectura para muchas aplicaciones. Pero de serie, MySQL a menudo tiene una ventaja.
Rendimiento de Escritura
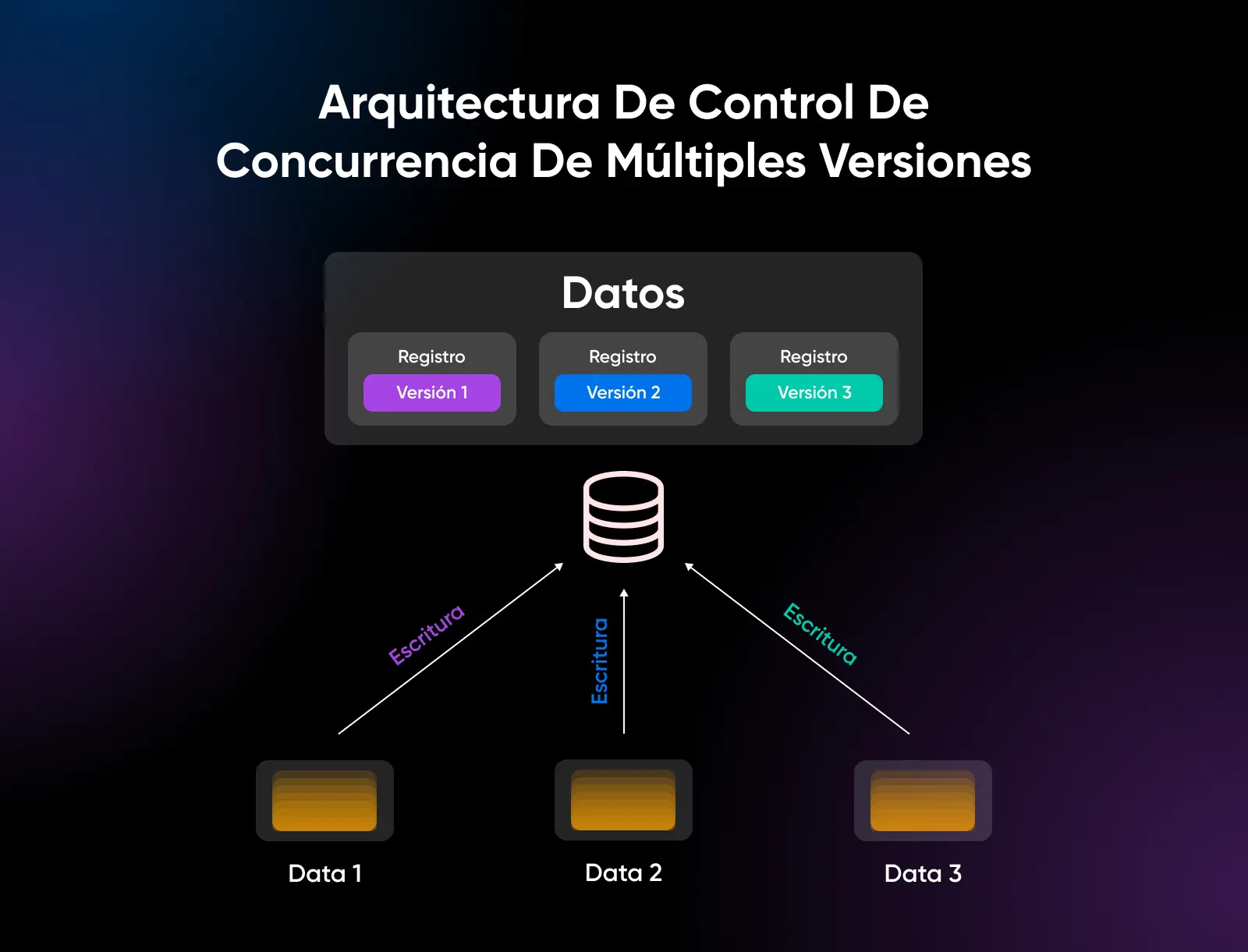
Cuando se trata de rendimiento de escritura, incluidas las cargas de trabajo masivas y consultas complejas que modifican datos, el consenso general es que PostgreSQL funciona mejor.
Su arquitectura de control de concurrencia de múltiples versiones (MVCC) le da a PostgreSQL una ventaja importante al permitir que múltiples sesiones actualicen datos con un bloqueo mínimo de forma concurrente.
Si tu aplicación necesita admitir muchos usuarios concurrentes modificando datos, el rendimiento de escritura de PostgreSQL puede superar lo que MySQL puede lograr.
Rendimiento de Consultas Complejas
Para consultas analíticas avanzadas que realizan escaneos de tablas grandes, clasificaciones o funciones de análisis, PostgreSQL también supera a MySQL en muchos casos, y lo hace con un margen significativo.
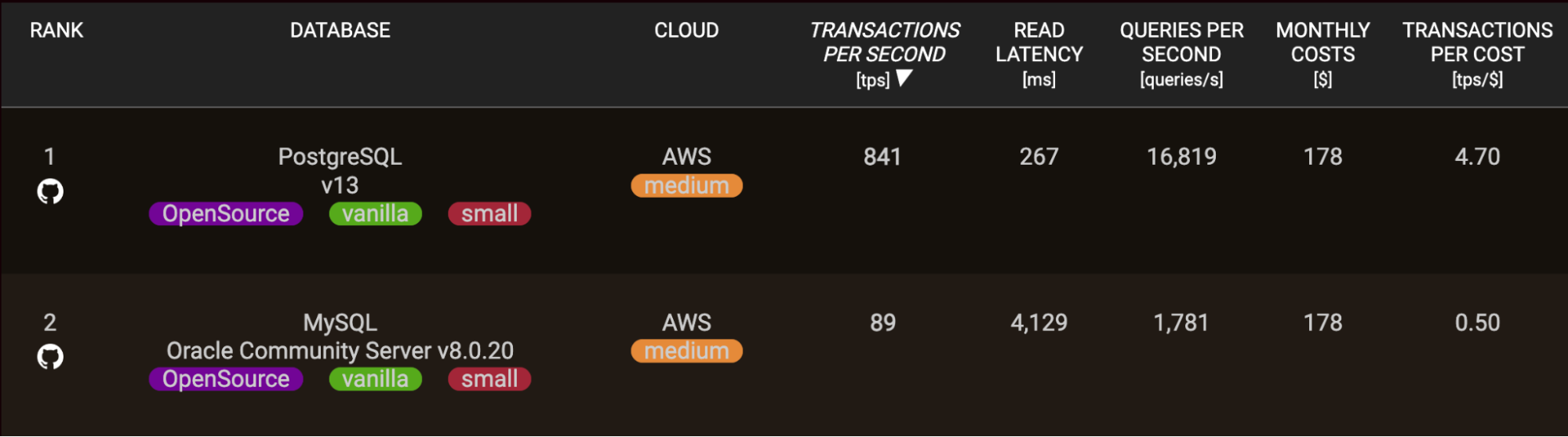
El optimizador de consultas SQL maduro de PostgreSQL y el soporte para sintaxis SQL avanzada le dan una ventaja para ejecutar rápidamente consultas analíticas intrincadas. MySQL ha mejorado significativamente recientemente, pero depende más del ajuste manual de consultas.
Entonces, para necesidades de inteligencia empresarial o almacenes de datos donde importa el rendimiento complejo de SQL multi-tabla, PostgreSQL a menudo destaca.
La Configuración Afecta el Rendimiento
Por supuesto, las bases de datos se pueden configurar y optimizar para adaptarse a diferentes cargas de trabajo. Entonces, para cualquier caso de uso, el “mejor” sistema aún depende significativamente del hardware del servidor subyacente, el sistema operativo, el subsistema de almacenamiento, la configuración de la base de datos y el diseño del esquema.
BenchANT hace un gran trabajo mostrando cómo diferentes servidores pueden afectar el rendimiento de una base de datos.
Junto con eso, la configuración de hardware también tiene un impacto significativo en el rendimiento de tu base de datos. Por ejemplo, si usas un VPS con almacenamiento NVMe, el almacenamiento subyacente es mucho más rápido que un disco duro regular, por lo que tus operaciones de base de datos serán extremadamente rápidas.
Sin embargo, no hay un sistema universalmente más rápido: tu experiencia variará según tu entorno y ajustes.
“La gestión de conexiones es el mejor argumento para MySQL. Sin embargo, en realidad no hay una razón real para no usar PostgreSQL en cualquier caso de uso relacional. Esto es especialmente cierto si consideras los desarrollos de los últimos 3 años. PostgreSQL está años por delante de cualquier competidor cuando se trata de bases de datos relacionales e incluso más allá de eso. La comunidad en crecimiento, el código fuente increíblemente organizado y la documentación casi divina son solo tres de los argumentos ganadores”.
— usuario de Reddit, themusician985
Cuándo Considerar MySQL
MySQL a menudo supera a PostgreSQL, utilizando menos recursos del sistema para esquemas simples y aplicaciones dominadas por un acceso de lectura rápido de clave-valor. Las aplicaciones web y móviles con mayores necesidades de escalabilidad, disponibilidad y lecturas distribuidas pueden beneficiarse de las fortalezas de MySQL.
Cuándo Considerar PostgreSQL
Las ventajas arquitectónicas de PostgreSQL hacen que valga la pena considerarlo para cargas de trabajo que requieren patrones de acceso a escritura complejos, consultas de análisis empresarial o flexibilidad en los tipos de datos. Si tienes administradores de bases de datos disponibles para la configuración y la optimización de consultas, PostgreSQL proporciona una base competente.
Comparación de Características Entre PostgreSQL y MySQL
Ambas bases de datos son completas, pero muestran diferencias considerables en los tipos de datos admitidos, funciones y conjuntos de características en general.
Soporte de Tipos de Datos
| Función | PostgreSQL | MySQL |
| Tipos de Datos | Soporte robusto integrado para JSON, XML, arrays, geo espaciales, de red, etc. | Depende más de las extensiones JSON |
| Lenguajes Funcionales | SQL, C, Python, JavaScript | Principalmente SQL |
| Soporte GIS | Excelente a través de la extensión espacial PostGIS | Limitado, a menudo requiere complementos |
PostgreSQL admite un conjunto más amplio de tipos de datos nativos, lo que permite una mayor flexibilidad en los esquemas de tu base de datos:
- Tipos geométricos para sistemas GIS.
- Tipos de direcciones de red como IPV4/IPV6.
- JSON nativo y JSONB: JSON binario optimizado.
- Documentos XML.
- Tipos de arrays.
- Columnas con múltiples tipos de datos.
“Postgres tiene un buen manejo de arrays. Por lo tanto, puedes almacenar tipos de arrays como un array de enteros o un array de cadenas en tu tabla. También hay varias funciones y operadores de arrays para leer los arrays, manipularlos, y así sucesivamente.”
— usuario de Reddit, mwdb
MySQL tiene una tipificación de datos más básica, principalmente numérica, de fecha/hora y de cadenas, pero puede lograr una flexibilidad similar a través de columnas JSON o extensiones espaciales.
Lenguajes Funcionales
PostgreSQL permite escribir funciones y procedimientos almacenados en varios lenguajes: SQL, C, Python, JavaScript, y más, para una mayor flexibilidad.
En contraste, los procedimientos almacenados de MySQL deben estar codificados en SQL, mientras que aún puedes escribir la lógica de la aplicación en varios lenguajes de propósito general.
Entonces, si necesitas incrustar la lógica de la aplicación o cálculos complejos directamente en los procedimientos de la base de datos, PostgreSQL proporciona mucha más flexibilidad.
Soporte GIS
Para conjuntos de datos espaciales utilizados en aplicaciones de mapeo/geográficas, PostgreSQL ofrece una excelente funcionalidad integrada a través de su extensión PostGIS. Consultas de ubicación, puntos dentro de polígonos y cálculos de proximidad funcionan de manera nativa.
El soporte espacial de MySQL es más limitado a menos que adoptes un motor espacial de terceros como MySQL Spatial o Integration MySOL. Para sistemas GIS, PostgreSQL con PostGIS es generalmente una solución más sencilla y capaz.
Replicación
Ambas bases de datos ofrecen replicación, permitiendo que los cambios en la base de datos se sincronicen entre instancias. De serie, la replicación de PostgreSQL se basa en archivos WAL (Write Ahead Log), lo que permite que los sitios web se escalen para incorporar tantos servidores de bases de datos como desees.
Entonces, PostgreSQL facilita la escalabilidad de réplicas de lectura finamente sincronizadas con porciones de datos específicas que cambian. Para MySQL, pueden ser necesarias herramientas de terceros.
Arquitectura y escalabilidad
PostgreSQL y MySQL difieren sustancialmente en sus arquitecturas generales, lo que impacta en sus perfiles de escalabilidad y rendimiento.
El Modelo Objeto-Relacional de PostgreSQL
Un rasgo arquitectónico clave de PostgreSQL es su adhesión al modelo objeto-relacional, lo que significa que los datos pueden adquirir características similares a los objetos en la programación orientada a objetos. Por ejemplo:
- Las tablas pueden heredar propiedades de otras tablas.
- Los tipos de datos pueden tener comportamientos especializados.
- Las funciones son características de los tipos de datos.
Esta estructura Objeto-Relacional permite modelar datos del mundo real complejos más cerca de los objetos y entidades de la aplicación. Sin embargo, tiene un costo: se necesitan sistemas internos más elaborados para rastrear relaciones de datos más ricas.
Las extensiones objeto-relacionales proporcionan una excelente flexibilidad, pero resultan en una sobrecarga de rendimiento en comparación con un sistema estrictamente relacional.
El Modelo Relacional Puro de MySQL
En contraste, MySQL sigue un modelo puramente relacional centrado en esquemas de tablas de datos simples y relaciones a través de claves foráneas. Este modelo más simple se traduce en un buen rendimiento para cargas de trabajo transaccionales impulsadas por sitios web.
El uso avanzado de MySQL con operaciones JOIN extensas o lógica de negocio localizada se maneja mejor a través del código de aplicación en lugar de personalizaciones de base de datos. MySQL opta por la simplicidad sobre la flexibilidad en su arquitectura central.
A diferencia de PostgreSQL, MySQL es una base de datos puramente relacional sin características orientadas a objetos. Cada base de datos consta de tablas individuales sin herencia ni tipos personalizados. JSON recientemente ha proporcionado cierta flexibilidad de base de datos de documentos.
Sin embargo, al evitar las características de objetos, MySQL logra un rendimiento más alto fuera de la caja en muchas cargas de trabajo, pero carece de las capacidades de modelado más profundas de PostgreSQL.
Por lo tanto, MySQL es más rápido para datos simples, mientras que PostgreSQL se adapta mejor a la complejidad. Elija según sus necesidades de acceso y escalabilidad de datos.
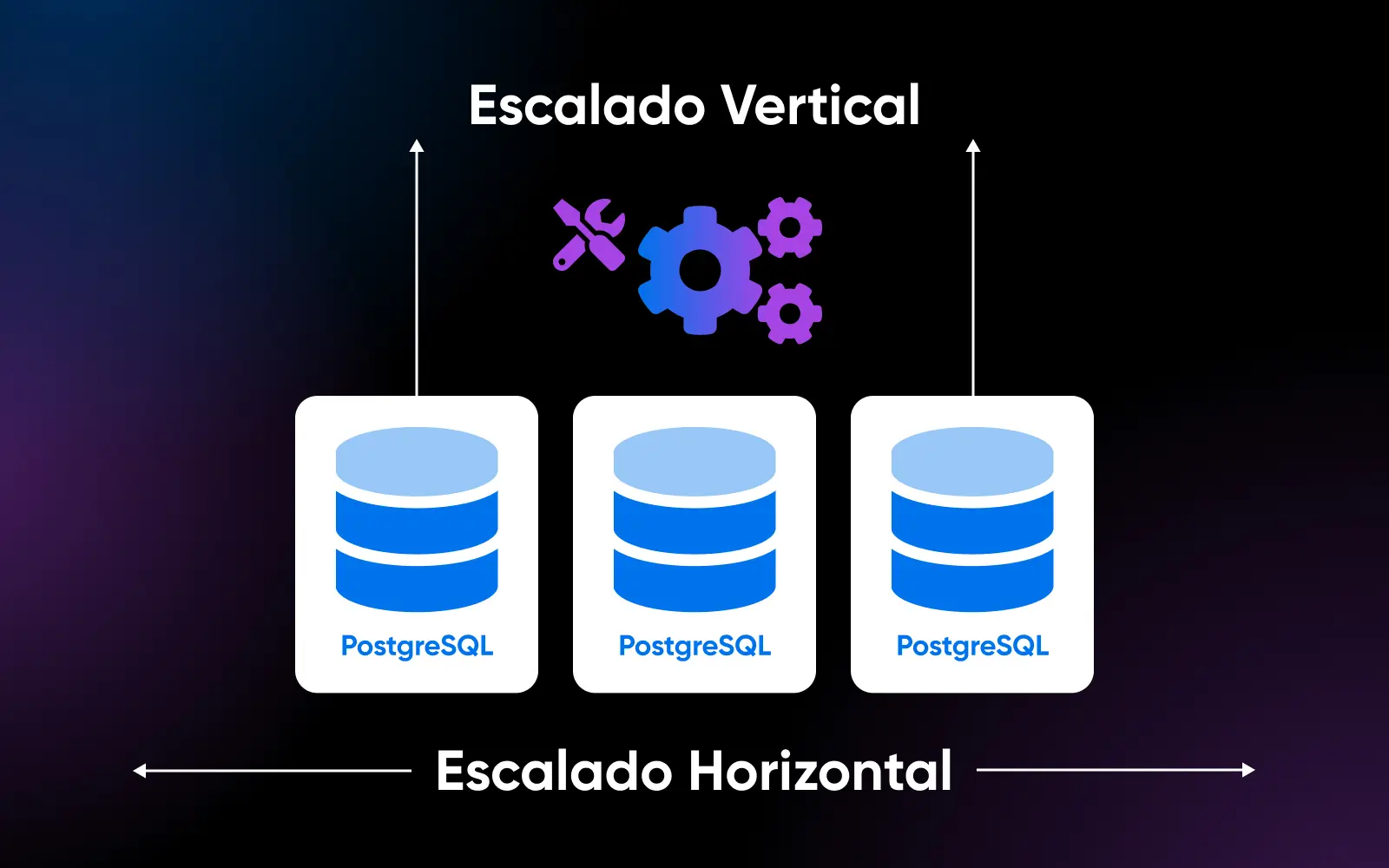
Escalado de Escritura con Control de Concurrencia de Múltiples Versiones (MVCC)
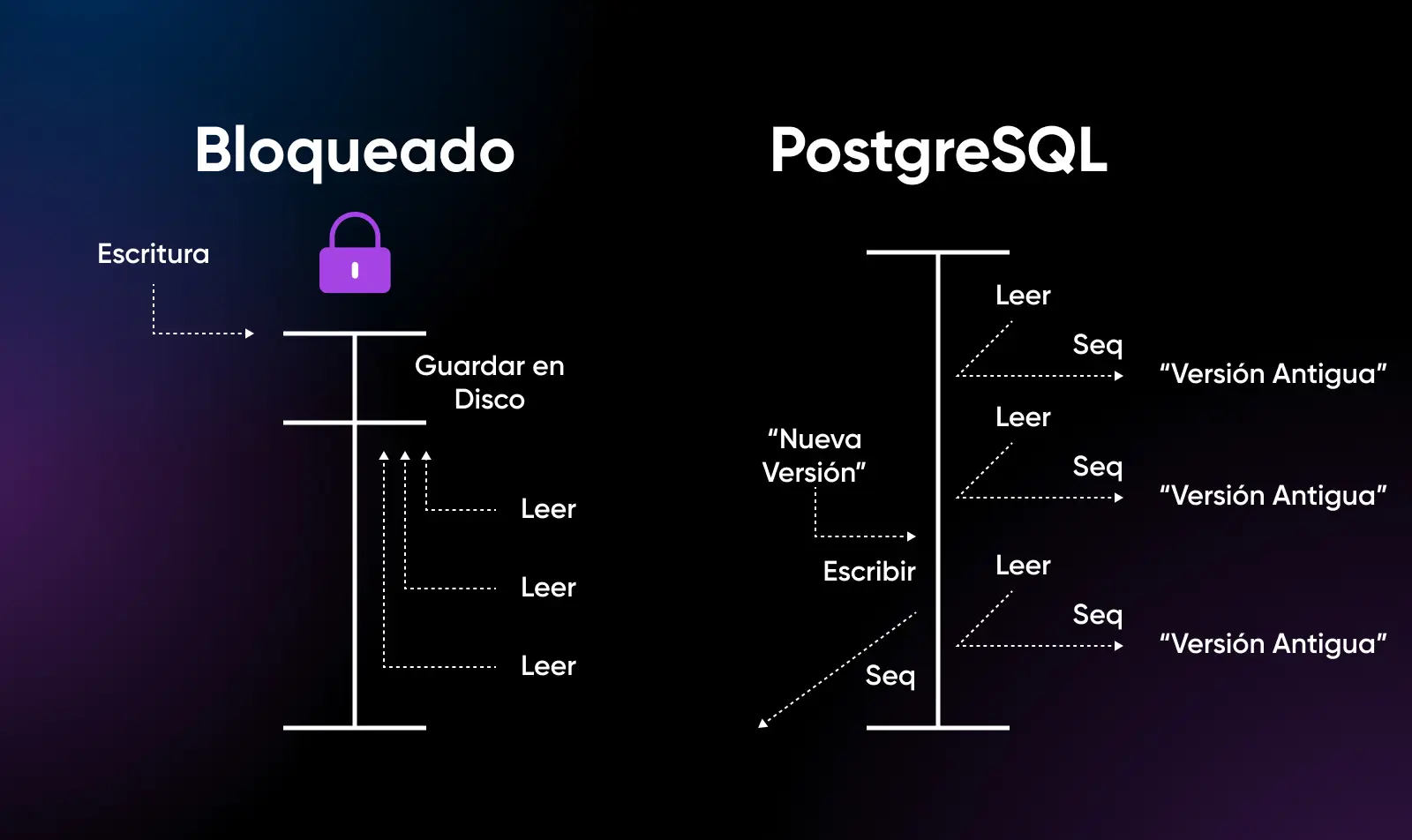
Un área en la que PostgreSQL sobresale particularmente es en el escalado horizontal de escritura, permitiendo que muchas sesiones concurrentes modifiquen datos en servidores distribuidos utilizando el modelo MVCC.
Este modelo MVCC significa una excelente concurrencia incluso para cargas de trabajo mixtas de lectura y escritura, lo que permite que las bases de datos de PostgreSQL escalen un gran rendimiento a través de la replicación. Las escrituras proceden en paralelo y luego se sincronizan después.
MySQL InnoDB logra una concurrencia similar utilizando bloqueos a nivel de fila en lugar de MVCC, pero la arquitectura de PostgreSQL ha demostrado ser más escalable bajo cargas de escritura altas en pruebas.
Esencialmente, PostgreSQL finalmente admite un mayor escalado de escritura, aunque con más sobrecarga del servidor. MySQL es más ligero para el escalado de lectura.
PostgreSQL Vs. MySQL: Fiabilidad Y Protección De Datos
PostgreSQL y MySQL ofrecen robustas protecciones de seguridad y mecanismos de fiabilidad, aunque PostgreSQL enfatiza la durabilidad, mientras que MySQL se enfoca en la alta disponibilidad.
Control De Acceso Y Encriptación
PostgreSQL y MySQL también proporcionan controles de cuentas de usuario, administración de privilegios y capacidades de encriptación de red para la seguridad. Elementos críticos como conexiones SSL, políticas de contraseña y seguridad basada en roles a nivel de fila se aplican de manera similar.
Sin embargo, hay algunas diferencias en torno a la encriptación:
- Encriptación nativa de datos en reposo: PostgreSQL 13 agregó el módulo pgcrypto para la encriptación de tabla de espacio de almacenamiento transparente del sistema de archivos. MySQL carece de encriptación nativa pero admite plugins.
- Políticas de acceso a filas livianas: PostgreSQL tiene RLS y MASK para roles para administrar la visibilidad de las filas hasta los dominios de datos a través de políticas. MySQL puede usar vistas para obtener un resultado similar, pero no es tan robusto.
Si bien ambos sistemas RDBMS protegen los datos sensibles mediante encriptación SSL/TLS para conexiones de cliente, PostgreSQL ofrece ligeramente más algoritmos de cifrado, monitoreo de actividades y opciones de control de acceso integradas que MySQL.
Fiabilidad de PostgreSQL a Través de WAL
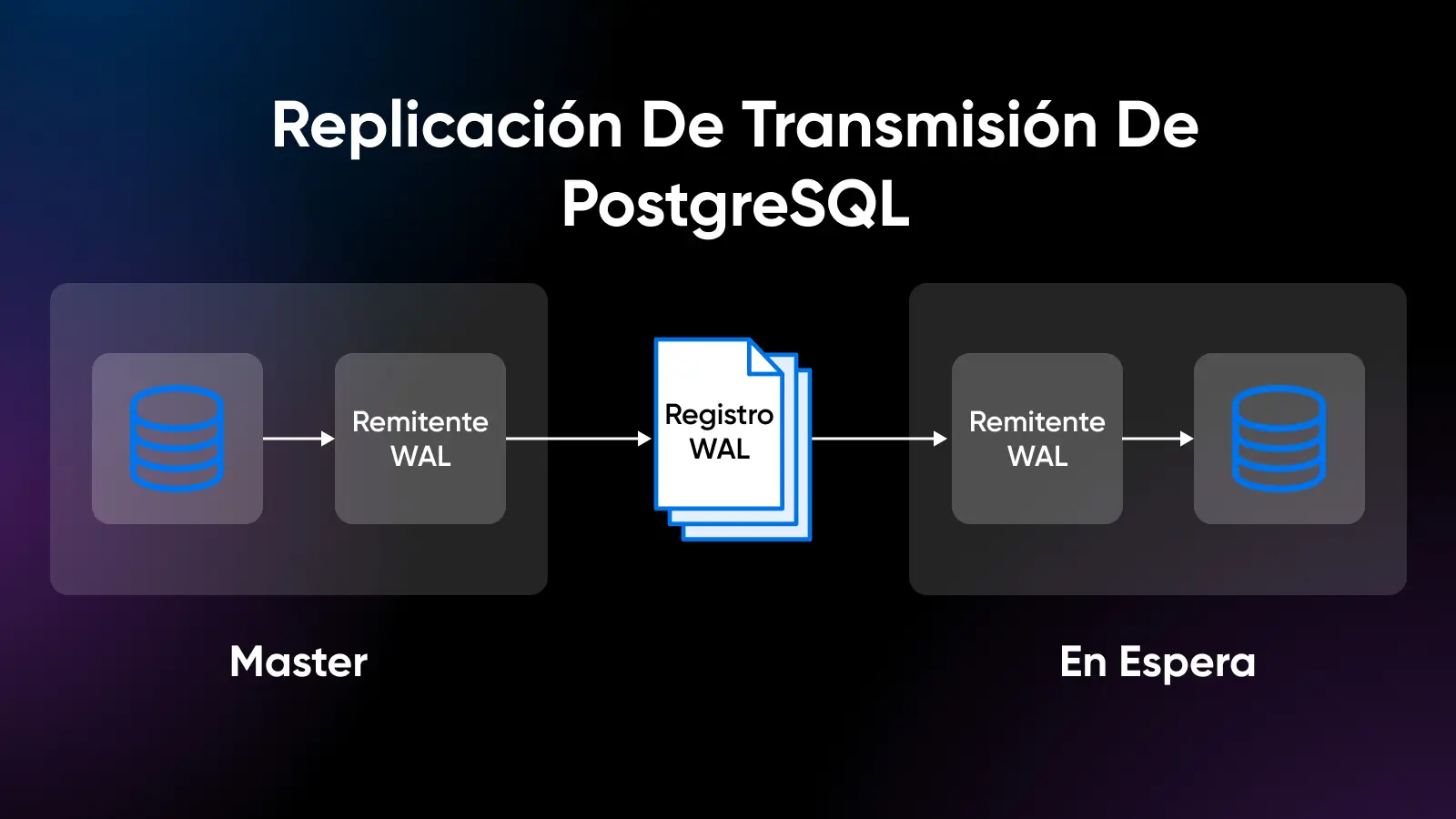
PostgreSQL utiliza el registro de escritura anticipada (WAL), donde los cambios de datos se registran en el registro antes de que ocurran las modificaciones de datos reales.
Esto protege contra la pérdida de datos, incluso en casos de accidentes o cortes de energía, evitando la corrupción de la base de datos.
Los registros WAL en PostgreSQL mantienen una cadena consistente de cambios en cola a través de transacciones que se pueden reproducir y recuperar datos rápidamente.
Este mecanismo alimenta características como la replicación de transmisión, consultas paralelas y recuperación en un punto en el tiempo (PITR) a estados anteriores en el tiempo sin necesidad de copias de seguridad completas.
En general, WAL ayuda a mantener garantías de durabilidad de datos y aumentos de rendimiento para la recuperación de accidentes y la replicación.
Disponibilidad Alta de MySQL
Para minimizar el tiempo de inactividad, MySQL ofrece un robusto agrupamiento de alta disponibilidad que se autodesplaza en caso de que se bloquee un solo servidor, con interrupción mínima. La promoción automática de réplicas y la rápida resincronización hacen que las interrupciones sean un caso raro.
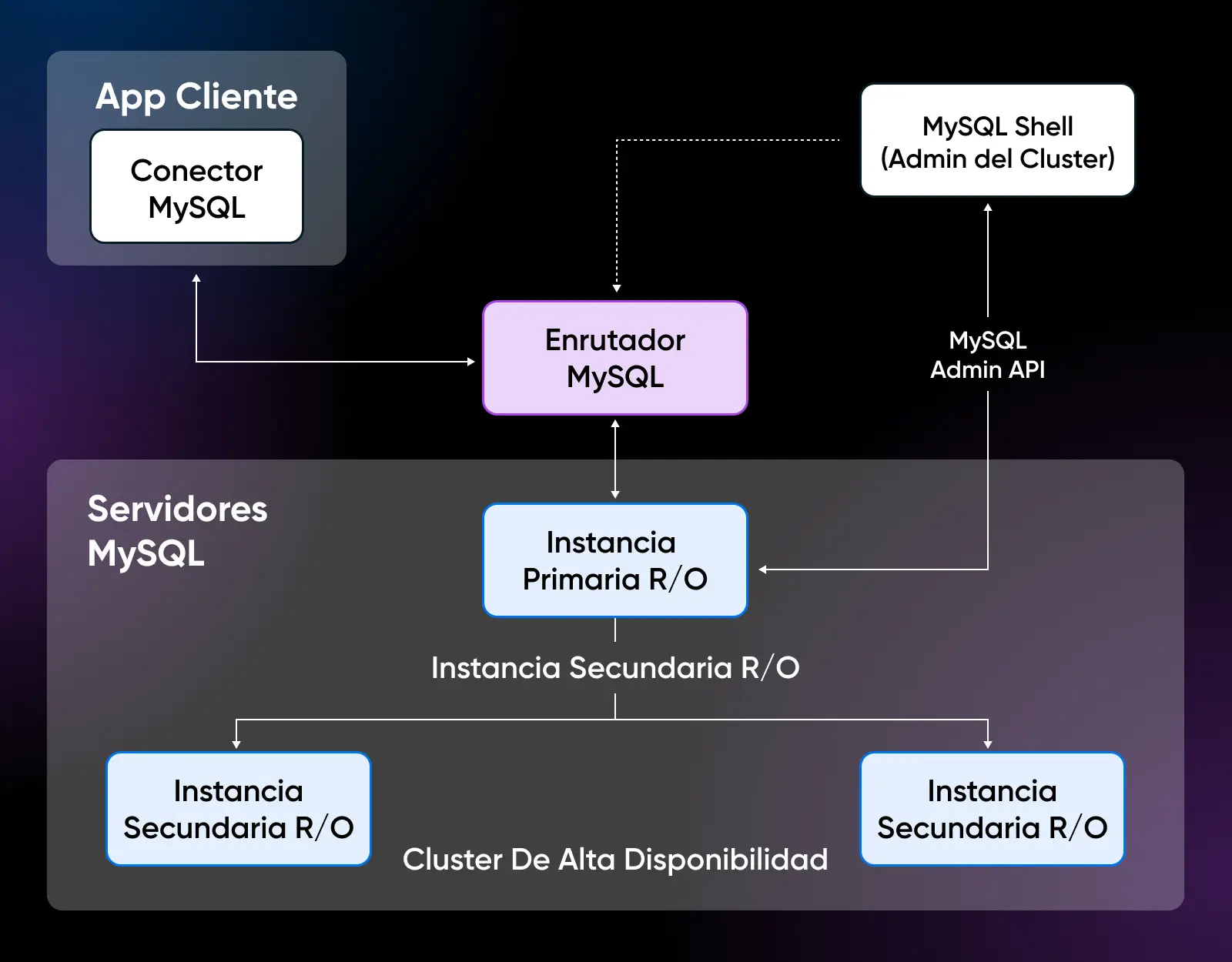
Si bien MySQL 5.7 no incluía alta disponibilidad integrada, MySQL 8 introdujo el clúster InnoDB para el cambio automático entre nodos.
PostgreSQL también logra alta disponibilidad a través de herramientas de replicación como Slony, Londiste o pgpool-II, que proporcionan un cambio de disparador o middleware. Sin embargo, PostgreSQL carece de la integración nativa de agrupamiento de MySQL, aunque se puede lograr alta disponibilidad.
Entonces, si su aplicación requiere un tiempo de actividad del servidor del 100% sin intervención manual, las capacidades de agrupamiento nativas de MySQL pueden servir mejor. Esa también es una de las razones por las que WordPress, un sistema de gestión de contenido que alimenta el 43% de Internet, continúa utilizando MySQL.
Soporte de la Comunidad y Bibliotecas
Dada la larga historia y las grandes bases de usuarios de ambos sistemas de bases de datos, PostgreSQL y MySQL ofrecen foros útiles, bibliotecas de documentación y herramientas de terceros. Sin embargo, algunas diferencias destacan.
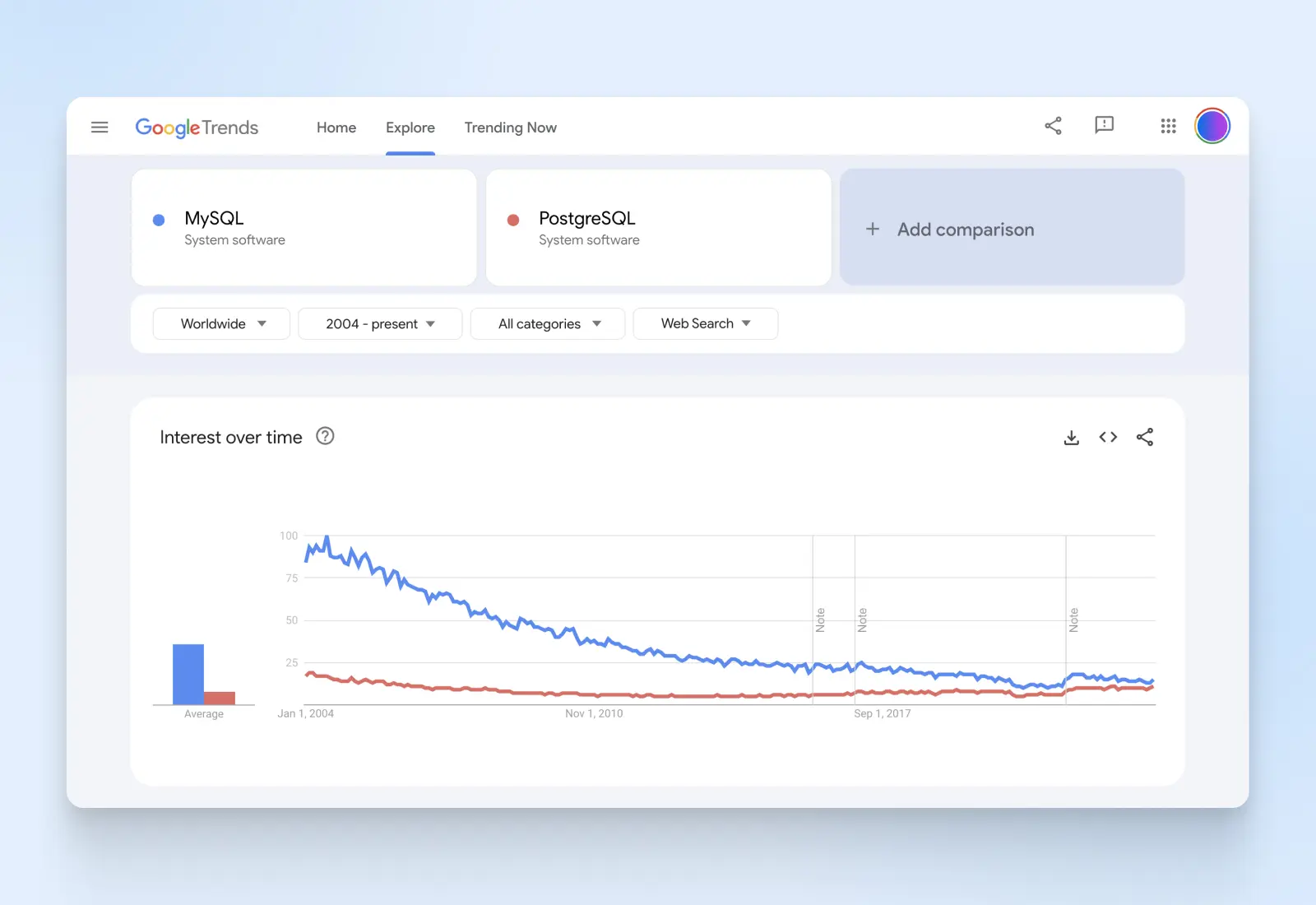
Según Google Trends, el interés en MySQL ha disminuido significativamente, acercándose más a PostgreSQL. Sin embargo, ambas bases de datos todavía tienen un gran seguimiento y base de usuarios, lo que les brinda un buen respaldo comunitario.
Comunidad de PostgreSQL
El desarrollo de PostgreSQL es gestionado por el Grupo de Desarrollo Global de PostgreSQL, un equipo de desarrolladores de la comunidad abierta que colaboran en todo el mundo. Miles de usuarios y colaboradores participan en las listas de correo electrónico, canales de IRC, blogs y eventos.
También organizan conferencias como PGConf, reuniendo periódicamente a la comunidad de Postgres. En general, un ecosistema de soporte sólido y capaz mantiene el progreso de PostgreSQL.
Comunidad de MySQL
Como una base de datos de código abierto enormemente popular, MySQL también cuenta con soporte comunitario en línea. La MySQL Developer Zone proporciona una documentación completa y foros para resolver problemas y siguientes pasos. Grandes conferencias como Percona Live discuten las últimas mejores prácticas utilizando MySQL.
La adquisición de MySQL por parte de Oracle también ayudó a obtener la inversión necesaria en nuevas versiones y ofertas de soporte comercial para aquellos que necesitan asistencia adicional. Aunque no es tan orgánico como PostgreSQL, los usuarios de MySQL tienen excelentes recursos comunitarios.
Comparación de la Profundidad del Soporte
Ambas bases de datos también tienen excelentes redes de soporte comunitario. PostgreSQL proporciona consejos técnicos más avanzados y una documentación excelente, dada la complejidad inherente de la base de datos. Su documentación también es un poco pícara, a diferencia de la mayoría de las otras documentaciones técnicas. Aquí tienes un extracto:
“El primer siglo comienza en 0001-01-01 00:00:00 AD, aunque no lo sabían en ese momento. Esta definición se aplica a todos los países con calendario gregoriano. No hay un número de siglo 0, se pasa de -1 siglo a 1 siglo. Si no está de acuerdo con esto, envíe su queja a: Papa, Catedral de San Pedro de Roma, Vaticano.”
— Documentación de PostgreSQL sobre EXTRACT, date_part
La comunidad de MySQL ofrece una experiencia más amplia perfeccionando casos de uso para principiantes como aplicaciones web.
Pero para cualquiera de las dos bases de datos, espera comunidades de usuarios comprometidas y solidarias listas para ayudar a guiar el uso y el crecimiento.
Casos de Utilización Típicos
Dadas las diferencias destacadas hasta ahora, PostgreSQL y MySQL tienden hacia algunos casos de uso distintos. Sin embargo, ambos sistemas RDBMS a menudo funcionan perfectamente bien para aplicaciones web que leen y escriben filas de datos.
Casos de Uso de PostgreSQL
PostgreSQL sobresale en cargas de trabajo analíticas muy pesadas en datos como:
- Inteligencia empresarial con consultas de agregado en ejecución complejas a través de millones de filas.
- Almacenamiento de datos e informes a través de muchas UNIONES de tablas y condiciones.
- La ciencia de datos y el machine learning requieren los tipos de datos de matriz, hstore, JSON y personalizados de PostgreSQL.
- Análisis geo espacial y multidimensional a través de PostGIS y procesamiento especializado. Ejemplos incluyen datos de ubicación en tiempo real, imágenes de satélite, datos climáticos y manipulación de geometría.
Estos aprovechan la flexibilidad de PostgreSQL.
Los casos de uso vertical específicos abundan en los sectores legal, médico, de investigación, de seguros, gubernamental y financiero que se están moviendo hacia la analítica de big data.
Ejemplos del mundo real incluyen Reddit, Apple, Instagram, investigación genética del sistema de hospitales Johns Hopkins, análisis publicitario de New York Times, seguimiento de clientes de ferrocarriles Amtrak, sistema de programación de empleados de Gap, registros de llamadas de Skype, etc.
Casos de Uso de MySQL
MySQL se enfoca en velocidad pura, simplicidad de desarrollo y escalabilidad inherente en aplicaciones web y móviles. Sus fortalezas particulares se destacan en:
- Procesamiento de transacciones en línea de alto rendimiento (OLTP) para sitios de comercio electrónico y aplicaciones web que necesitan un alto rendimiento en lecturas y escrituras que afectan a numerosas tablas discretas por fila. Piense en sitios maduros a escalas como Airbnb, Twitter, Facebook y Uber.
- Juegos masivos multijugador en línea (MMO) con una gran base de jugadores que se deben admitir de manera concurrente en tiempo casi real.
- Aplicaciones móviles y el Internet de las cosas (IoT) que requieren bases de datos compactas para incluir localmente o incrustar en dispositivos periféricos con sincronización ocasional de regreso a centros de datos.
- Plataformas de software como servicio (SaaS) multi-inquilino que escalan rápidamente las bases de datos según la demanda mientras mantienen los datos separados.
Estas aplicaciones priorizan la disponibilidad y la velocidad de lectura/escritura a escala web sobre las capacidades de análisis profundo o las herramientas de ciencia de datos. En 2016, Uber también cambió de PostgreSQL a MySQL, convirtiendo esta transición en tema de conversación en la comunidad tecnológica durante un tiempo.
Hay muchas empresas grandes que utilizan MySQL, incluidas WordPress, Wikipedia, Facebook, Google AdWords, Zendesk, Mint, Uber, Square, Pinterest, Github, Netflix (navegación de películas), metadatos de videos de YouTube, etc.
Migración de MySQL a PostgreSQL o Viceversa
Dada la popularidad de ambas bases de datos, muchos desarrolladores pueden migrar entre MySQL y PostgreSQL. ¿Qué deben esperar durante este proceso de migración de la base de datos?
En general, migrar bases de datos relacionales completamente funcionales entre MySQL y PostgreSQL funciona bastante bien en la mayoría de los casos, gracias a las excelentes herramientas de migración disponibles. La sintaxis y las funciones SQL coinciden mucho más que difieren. Los tipos de datos generalmente se traducen bien, aunque hacer conversiones de prueba ayuda.
Examinemos algunos desafíos clave a tener en cuenta:
Manejo de Cambios en los Tipos de Datos
Al migrar esquemas de MySQL a PostgreSQL o viceversa, preste atención a cualquier discrepancia en los tipos de datos:
- Las columnas AUTO_INCREMENT de MySQL se convierten en SERIAL en PostgreSQL.
- Los arreglos de PostgreSQL necesitan cambios de sintaxis adicionales ya que no hay un tipo de dato similar en MySQL.
- Verifica las conversiones de datos de fecha/hora.
Prueba las migraciones con copias de datos de producción para validar la fidelidad. Las discrepancias en los tipos de datos pueden romper fácilmente las aplicaciones si no se abordan.
Migración de Procedimientos Almacenados
Si dependes en gran medida de los procedimientos almacenados para la lógica comercial, migrarlos entre MySQL y PostgreSQL requiere reescribir código.
Las diferencias clave en sus lenguajes de procedimientos, como la sintaxis del delimitador, a menudo rompen la portabilidad del código. Además, confirme que los permisos permanezcan intactos para los procedimientos de producción.
Por lo tanto, valida tu migración minuciosamente y no asumas que las funciones se trasladan limpiamente entre plataformas.
Compatibilidad del Cliente
Las aplicaciones que dependen de las bibliotecas de clientes de PostgreSQL y MySQL también necesitan reconfigurarse al cambiar de entornos:
- Actualiza las cadenas de conexión.
- Reemplaza el uso de la biblioteca de cliente.
- Redirige las llamadas de la API a una nueva plataforma.
Cambiar la base de datos subyacente también requiere cambios en la aplicación. Integra la conectividad actualizada en tu lista de verificación de pruebas de migración.
Cambios en el Esquema a Partir de las Funciones de las Bases de Datos Relacionales
Evalúa la herencia de tablas de PostgreSQL, la seguridad a nivel de fila y los permisos de usuario ajustados frente a las vistas y los desencadenadores de MySQL para ver si la lógica debe cambiarse a construcciones nuevas y mejoradas disponibles en cada base de datos.
Las características que afectan la funcionalidad tienden a migrar de manera más limpia, manteniéndose más cerca de los estándares SQL.
Cambios en el Código de Aplicación
Actualiza las cadenas de conexión y los controladores utilizados, por supuesto. Además, optimiza las fortalezas de rendimiento de cada base de datos. MySQL puede aprovechar más las uniones y la lógica de presentación del lado de la aplicación, que ahora está puramente en SQL en PostgreSQL. Por otro lado, PostgreSQL puede implementar ahora enfoques de reglas comerciales que antes solo eran posibles a través de los desencadenadores y los procedimientos almacenados de MySQL.
Afortunadamente, muchos marcos de acceso a datos como Hibernate abstractan algunas diferencias de los desarrolladores al limitar la sintaxis propietaria expuesta. Evalúe si los cambios en ORM o cliente también tienen sentido.
Una planificación adecuada, evaluaciones del impacto del cambio y entornos de puesta en escena minimizan el estrés de la migración para aprovechar con éxito lo mejor que ofrece cada base de datos.
Utiliza Herramientas de Migración
Afortunadamente, existen herramientas que ayudan a mover esquemas y datos entre MySQL y PostgreSQL con mayor facilidad:
- pgLoader: Utilidad popular de migración de datos para trasladarse a PostgreSQL.
- AWS SCT: Convertidor de bases de datos para migraciones homogéneas.
Estas herramientas suavizan automáticamente muchos problemas de compatibilidad entre sistemas operativos y entornos, garantizando datos idénticos en todos los sistemas.
Así que guarda tiempo para la conversión/pruebas, pero utiliza herramientas automatizadas para cambiar de bases de datos.
¿Cuál Es la Base de Datos Adecuada Para Ti?
Decidir entre PostgreSQL y MySQL depende en gran medida de los requisitos específicos de tu aplicación y las habilidades del equipo, pero algunas preguntas clave pueden orientar tu decisión:
¿Qué tipos de datos almacenarás? Si necesitas trabajar con datos más complejos e interconectados, los tipos de datos flexibles y el modelo objeto-relacional de PostgreSQL hacen que eso sea mucho más sencillo.
¿Qué tan crítica es la eficiencia de las consultas y la escalabilidad? MySQL maneja mejor el rendimiento del flujo de trabajo para aplicaciones web de alto tráfico que exigen lecturas más rápidas. Pero PostgreSQL ha demostrado ser más sólido para cargas de trabajo mixtas de lectura y escritura a escala empresarial.
¿Qué habilidades de administración tiene tu equipo? PostgreSQL recompensa la experiencia avanzada en bases de datos, dada su amplia configurabilidad. MySQL es más sencillo para los administradores sin excelentes habilidades de SQL para ponerse en marcha productivamente.
Plataformas como DreamHost hacen que el alojamiento de servidores de bases de datos sea fácil y sencillo con VPS, servidores dedicados y alojamiento en la nube. DreamHost se encarga de la seguridad y las copias de seguridad automáticas para simplificar las operaciones, para que puedas concentrarte en utilizar los datos para obtener información empresarial.
Así que deja que el equipo de Bases de Datos de DreamHost se encargue de la implementación y administración, mientras tú diseñas la plataforma de datos ideal para tu crecimiento. PostgreSQL y MySQL ofrecen economía de código abierto con fiabilidad empresarial cuando están respaldados por expertos en la nube probados. La mejor base de datos para tu aplicación probablemente esté esperando; ¡pruébala hoy mismo!

Bases de Datos al Alcance de Tus Manos
¡Optimiza tu rendimiento y asegura la estabilidad de tus bases de datos! ¡Mejora tu infraestructura ahora mismo para un funcionamiento óptimo de tus aplicaciones!
