
Linux ist das Rückgrat des Internets. Es treibt fast 97% der weltweit führenden Webserver an. Und 55,9% der professionellen Entwickler setzen auf Linux für ihre Entwicklungsbedürfnisse.
Dennoch hat Linux nur einen Desktop-Marktanteil von 2,68%. Warum diese Lücke?
Der Kernfokus von Linux lag niemals auf seiner Benutzeroberfläche. Stattdessen wurde es so konzipiert, dass es Ihnen vollständige Kontrolle über Ihr Betriebssystem durch die Befehlszeile gibt.
Das kann Linux für Anfänger einschüchternd erscheinen lassen — Und die Tausenden verfügbarer Befehle machen dies nur noch schwieriger.
In diesem Artikel behandeln wir die 100 nützlichsten Linux-Befehle. Das Erlernen nur einer Handvoll dieser Befehle kann Ihnen helfen, Ihre Produktivität als Linux-Benutzer zu steigern. Lassen Sie uns gleich eintauchen!
Linux
Linux bezieht sich auf eine Sammlung von quelloffenen Betriebssystemen (OS). Es gibt nicht ein einzelnes Linux-OS. Stattdessen können Benutzer aus einer breiten Gruppe von Linux-Distributionen wählen, die alle unterschiedliche Erfahrungen bieten.
Mehr lesenWas sind Linux-Befehle?
Linux-Befehle ermöglichen es Ihnen, Ihr System über die Befehlszeilenschnittstelle (CLI) anstelle Ihrer Maus oder Ihres Trackpads zu steuern. Es handelt sich um Textanweisungen, die in das Terminal eingegeben werden, um Ihrem System genau zu sagen, was es tun soll.
Befehle, die Sie im Linux-Terminal eingeben, sind groß- und kleinschreibungsempfindlich und folgen einer Syntax wie „command -options arguments.“ Sie können sie für komplexe Aufgaben mit Pipelines und Umleitungen kombinieren.
Einige wichtige Dinge, die man über Linux-Befehle wissen sollte:
- Sie sind groß- und kleinschreibungsempfindlich; zum Beispiel bedeuten „
ls“ und „LS“ unterschiedliche Dinge. - Sie folgen einer spezifischen Syntax wie „
command -options arguments„. - Sie können kombiniert werden für komplexe Operationen mittels Pipelines und Umleitungen.
- Sie ermöglichen eine detaillierte Steuerung über Ihr System, was mit grafischen Schnittstellen schwer zu erreichen ist.
- Sie ermöglichen es Ihnen, Aufgaben zu automatisieren durch Shell-Skripte und Stapelverarbeitung.
- Sie können verwendet werden, um auf Systemressourcen zuzugreifen wie das Dateisystem, Netzwerk, Speicher und CPU.
- Sie bilden die Grundlage der Interaktion mit Linux Servern und Betriebssystemen.
Wenn Sie ein Programmierer sind, der gerade das Programmieren lernt, können Sie Ihre Linux-Befehle üben, ohne Windows verlassen zu müssen, indem Sie das Windows-Subsystem für Linux verwenden. Dies ermöglicht es Ihnen, Linux innerhalb von Windows zu betreiben, ohne einen Dual-Boot durchführen zu müssen und das Beste aus beiden Betriebssystemen zu holen.
Top 100 der nützlichsten Linux-Befehle
Jetzt, da Sie ein grundlegendes Verständnis dafür haben, was Linux-Befehle sind, lassen Sie uns in die Top 100 der am häufigsten verwendeten Linux-Befehle eintauchen.
Wir haben sie nach Kategorien geordnet, um Bereiche wie Dateiverwaltung, Systemüberwachung, Netzwerkoperationen, Benutzerverwaltung und mehr abzudecken.
Dateiverwaltungsbefehle in Linux
Dateiverwaltung ist eine häufige Aufgabe in der Linux-Befehlszeile. Hier sind wesentliche Dateibefehle:
1. ls – Verzeichnisinhalte auflisten
Der ls Befehl ist einer der am häufigsten verwendeten Linux-Befehle. Er listet den Inhalt eines Verzeichnisses auf, indem er alle Dateien und Unterverzeichnisse anzeigt, die darin enthalten sind.
Ohne jegliche Optionen oder Argumente zeigt ls den Inhalt des aktuellen Arbeitsverzeichnisses an. Sie können einen Pfadnamen übergeben, um Dateien und Ordner an diesem Ort anzuzeigen.
Syntax:
ls [Optionen] [Verzeichnis] |
Einige der nützlichsten ls Optionen umfassen:
-l– Ergebnisse im Langformat anzeigen, wobei zusätzliche Details wie Berechtigungen, Eigentum, Größe und Änderungsdatum für jede Datei und jedes Verzeichnis angezeigt werden.-a– Versteckte Dateien und Verzeichnisse, die mit einem Punkt beginnen, zusätzlich zu nicht versteckten Elementen anzeigen.-R– Rekursiv den Inhalt aller Unterverzeichnisse auflisten und unbegrenzt in Kinderordner hinabsteigen.-S– Ergebnisse nach Dateigröße sortieren, die größten zuerst.-t– Nach Zeitstempel sortieren, die neuesten zuerst.
Beispiel:
ls -l /home/user/documents |
Dies würde den Inhalt des Ordners „documents“ im Langformat auflisten.
Beispiel Ausgabe:
Insgesamt 824-rwxrwx--- 1 Benutzer Benutzer 8389 Jul 12 08:53 report.pdf-rw-r--r-- 1 Benutzer Benutzer 10231 Jun 30 16:32 presentation.pptxdrwxr-xr-x 2 Benutzer Benutzer 4096 Mai 11 09:21 images-rw-rw-r-- 1 Benutzer Benutzer 453 Apr 18 13:32 todo.txt |
Diese Ausgabe zeigt eine detaillierte Liste mit Berechtigungen, Größe, Eigentümer und Zeitstempel für jede Datei und jedes Verzeichnis. Das lange Listenformat, das durch die -l Option bereitgestellt wird, bietet auf einen Blick hilfreiche Dateiinformationen.
Der ls Befehl bietet Ihnen flexible Kontrolle über die Auflistung von Verzeichnisinhalten. Es ist eines der Befehle, die Sie ständig verwenden werden, wenn Sie mit Linux arbeiten.
2. cd – Verzeichnis wechseln
Der Befehl cd wird verwendet, um zwischen Verzeichnissen zu navigieren. Er ermöglicht es Ihnen, das aktuelle Arbeitsverzeichnis an einen neuen Ort im Dateisystem zu verschieben.
Wenn Sie den Befehl cd alleine ausführen, werden Sie zum Home-Verzeichnis zurückgeführt. Sie können auch einen spezifischen Pfad angeben, in den gewechselt werden soll. Zum Beispiel:
cd /usr/local– Wechselt in das Verzeichnis /usr/local.cd ..– Geht eine Ebene höher zum übergeordneten Verzeichnis.cd ~/pictures– Wechselt in den Ordner Bilder in Ihrem Home-Verzeichnis.
Syntax:
cd [directory]
Beispiel:
cd /home/user/documents
Dies würde das Arbeitsverzeichnis in den Ordner „documents“ unter /home/user ändern. Die Verwendung von cd ist wesentlich, um auf Dateien an verschiedenen Orten bequem zugreifen und mit ihnen arbeiten zu können.
3. mkdir – Ein neues Verzeichnis erstellen
Der mkdir Befehl erlaubt es Ihnen, einen neuen Ordner zu erstellen. Sie geben einfach den Namen des zu erstellenden Verzeichnisses an.
Syntax:
mkdir [options] <directory>
Dies wird ein Verzeichnis namens „newproject“ im aktuellen Arbeitsverzeichnis erstellen.
Einige nützliche mkdir Optionen:
-p– Erstellt übergeordnete Verzeichnisse nach Bedarf rekursiv.-v– Ausführliche Ausgabe, die erstellte Verzeichnisse anzeigt.
Beispiel:
mkdir -v ~/project/code
Dies würde das Unterverzeichnis „code“ unter „project“ im Home-Verzeichnis des Benutzers erstellen, mit ausführlicher Ausgabe, die die Erstellung des Verzeichnisses zeigt.
4. rmdir – Verzeichnis entfernen
Um ein leeres Verzeichnis zu löschen, verwenden Sie den Befehl rmdir. Beachten Sie, dass rmdir nur leere Verzeichnisse entfernen kann – wir benötigen den Befehl rm, um nicht-leere zu löschen.
Syntax:
rmdir [options] <directory>
Einige Optionen für rmdir umfassen:
-v– Ausführliche Ausgabe beim Löschen von Verzeichnissen.-p– Übergeordnete Verzeichnisse bei Bedarf rekursiv entfernen.
Beispiel:
rmdir -v ~/project/code
Dies würde das Unterverzeichnis „code“ unter „project“ löschen, während eine ausführliche Ausgabe angezeigt wird.
5. touch – Eine neue leere Datei erstellen
Der Befehl touch wird verwendet, um sofort eine neue leere Datei zu erstellen. Dies ist nützlich, wenn Sie später eine leere Datei mit Daten füllen müssen.
Die grundlegende Syntax von touch lautet:
touch [options] filename
Einige nützliche Optionen für touch umfassen:
-c– Erstellen Sie die Datei nicht, wenn sie bereits existiert. Dies vermeidet das versehentliche Überschreiben bestehender Dateien.-m– Anstatt eine neue Datei zu erstellen, aktualisieren Sie den Zeitstempel einer bestehenden Datei. Dies kann verwendet werden, um die Änderungszeit zu ändern.
Zum Beispiel:
touch /home/user/newfile.txt
Der obige Befehl erstellt eine neue leere Datei namens „newfile.txt“ im Verzeichnis /home/user des Benutzers. Wenn newfile.txt bereits existiert, werden stattdessen die Zugriffs- und Änderungszeiten der Datei aktualisiert.
6. cp – Dateien und Verzeichnisse kopieren
Der cp Befehl kopiert Dateien oder Verzeichnisse von einem Ort zu einem anderen. Es erfordert die Angabe eines Quellpfades und eines Ziels.
Die grundlegende Syntax von cp lautet:
cp [options] source destination
Einige nützliche cp Optionen:
-r– Verzeichnisse rekursiv kopieren, in Unterverzeichnisse absteigen und deren Inhalt ebenfalls kopieren. Notwendig beim Kopieren von Verzeichnissen.-i– Vor dem Überschreiben vorhandener Dateien am Zielort nachfragen. Es verhindert das versehentliche Überschreiben von Daten.-v– Ausführliche Ausgabe anzeigen, die die Details jeder kopierten Datei zeigt. Hilfreich, um genau zu bestätigen, was kopiert wurde.
Zum Beispiel:
cp -r /home/user/documents /backups/
Dies würde das Verzeichnis /home/user/documents und alle seine Inhalte rekursiv in das Verzeichnis /backups/ kopieren. Die Option -r wird benötigt, um Verzeichnisse zu kopieren.
Der cp Befehl ist eines der am häufigsten verwendeten Dienstprogramme zur Dateiverwaltung zum Kopieren von Dateien und Verzeichnissen in Linux. Sie werden feststellen, dass Sie diesen Befehl recht häufig verwenden.
7. mv – Verschieben oder Umbenennen von Dateien und Verzeichnissen
Der Befehl mv wird verwendet, um Dateien oder Verzeichnisse an einen anderen Ort zu verschieben oder sie umzubenennen. Im Gegensatz zum Kopieren werden die Dateien vom Quellpfad gelöscht, nachdem sie an den Zielort verschoben wurden.
Sie können auch den Befehl mv verwenden, um Dateien umzubenennen, da Sie einfach die Quell- und Zielpfade auf den alten und neuen Namen ändern müssen.
Die Syntax von mv lautet:
mv [options] source destination
Nützliche mv Optionen:
-i– Aufforderung vor dem Überschreiben vorhandener Dateien am Zielort. Dies verhindert ein versehentliches Überschreiben von Daten.-v– Erzeugt eine ausführliche Ausgabe, die jede Datei oder jedes Verzeichnis anzeigt, während es verschoben wird. Dies hilft zu bestätigen, was genau verschoben wurde.
Zum Beispiel:
mv ~/folder1 /tmp/folder1
Das oben Genannte wird den Ordner1 vom Startverzeichnis (~) in das Verzeichnis /tmp/ verschieben. Lassen Sie uns ein weiteres Beispiel für die Verwendung des mv Befehls zum Umbenennen von Dateien ansehen.
mv folder1 folder2
Hier wird „folder1“ in „folder2.“ umbenannt
8. rm – Dateien und Verzeichnisse entfernen
Der rm Befehl löscht Dateien und Verzeichnisse. Seien Sie vorsichtig, da gelöschte Dateien und Verzeichnisse nicht wiederhergestellt werden können.
Die Syntax lautet:
rm [options] name
Nützliche rm Optionen:
-r– Verzeichnisse rekursiv löschen, einschließlich aller Inhalte darin. Dies ist notwendig, wenn Verzeichnisse gelöscht werden.-f– Löschung erzwingen und alle Bestätigungsaufforderungen unterdrücken. Dies ist ein gefährlicher Befehl, da Dateien nicht wiederhergestellt werden können, wenn sie einmal gelöscht sind!-i– Vor dem Löschen jeder Datei oder jedes Verzeichnisses um Bestätigung bitten, was Sicherheit gegen versehentliches Entfernen bietet.
Beispielweise:
rm -rf temp
Dies löscht rekursiv das Verzeichnis „temp“ und alle seine Inhalte ohne Nachfrage (-f überschreibt Bestätigungen).
Hinweis: Der rm-Befehl löscht Dateien und Ordner dauerhaft, verwenden Sie ihn daher mit äußerster Vorsicht. Wenn er mit Sudo-Berechtigungen verwendet wird, könnten Sie auch das Root-Verzeichnis vollständig löschen, und Linux würde nach einem Neustart Ihres Computers nicht mehr funktionieren.
9. find – Suche nach Dateien in einer Verzeichnishierarchie
Der find Befehl durchsucht rekursiv Verzeichnisse nach Dateien, die den angegebenen Kriterien entsprechen.
Die grundlegende Syntax von find ist:
find [Pfad] [Kriterien]
Einige nützliche Kriterienoptionen für die Suche beinhalten:
-type f– Suche nur nach normalen Dateien, ohne Verzeichnisse.-mtime +30– Suche nach Dateien, die vor über 30 Tagen geändert wurden.-user jane– Suche nach Dateien, die dem Benutzer „jane“ gehören.
Zum Beispiel:
find . -type f -mtime +30
Dies wird alle regulären Dateien finden, die älter als 30 Tage sind, im aktuellen Verzeichnis (durch den Punkt gekennzeichnet).
Der Befehl find ermöglicht die Suche nach Dateien basierend auf einer Vielzahl von fortgeschrittenen Bedingungen wie Name, Größe, Berechtigungen, Zeitstempeln, Besitz und mehr.
10. du – Schätzung der Speichernutzung von Dateien
Der du Befehl misst den Speicherverbrauch für ein gegebenes Verzeichnis. Wenn er ohne Optionen verwendet wird, zeigt er den Festplattenverbrauch für das aktuelle Arbeitsverzeichnis an.
Die Syntax für du lautet:
du [options] [path]
Nützliche du Optionen:
-h– Dateigrößen in einem menschenlesbaren Format wie K für Kilobytes anzeigen, anstatt einer Byteanzahl. Viel einfacher zu verstehen.-s– Nur die Gesamtgröße für ein Verzeichnis anzeigen, anstatt jedes Unterverzeichnis und jede Datei aufzulisten. Gut für eine Zusammenfassung.-a– Einzelne Dateigrößen zusätzlich zu Gesamtwerten anzeigen. Hilft, große Dateien zu identifizieren.
Zum Beispiel:
du -sh pictures
Dies wird eine für Menschen lesbare Gesamtgröße für das Verzeichnis „pictures“ ausgeben.
Der du Befehl ist hilfreich zur Analyse der Speichernutzung für einen Verzeichnisbaum und zur Identifizierung von Dateien, die übermäßig viel Platz verbrauchen.
Such- und Filterbefehle in Linux
Nun, lassen Sie uns Befehle erkunden, die es Ihnen ermöglichen, direkt von der Linux-Befehlszeile aus zu suchen, zu filtern und Text zu manipulieren.
11. grep – Textsuche mit Mustern
Der grep Befehl wird verwendet, um nach Textmustern in Dateien oder Ausgaben zu suchen. Er druckt alle Zeilen, die mit dem gegebenen regulären Ausdruck übereinstimmen. grep ist extrem mächtig für die Suche, Filterung und Musterabgleich in Linux.
Hier ist die grundlegende Syntax:
grep [options] pattern [files]
Zum Beispiel:
grep -i "error" /var/log/syslog
Diese Suche durchforstet die Syslog-Datei nach dem Wort „error“, wobei die Groß- und Kleinschreibung ignoriert wird.
Einige nützliche grep Optionen:
-i– Unterschiede in Mustern ignorieren-R– Rekursiv in Unterverzeichnissen suchen-c– Nur die Anzahl der übereinstimmenden Zeilen ausgeben-v– Übereinstimmung umkehren, nicht übereinstimmende Zeilen ausgeben
grep ermöglicht es Ihnen, Dateien und Ausgaben schnell nach Schlüsselwörtern oder Mustern zu durchsuchen. Es ist unverzichtbar für das Parsen von Protokollen, das Durchsuchen von Quellcode, das Abgleichen von Regexen und das Extrahieren von Daten.
12. awk – Mustersuch- und Verarbeitungssprache
Der awk-Befehl ermöglicht erweiterte Textverarbeitung basierend auf spezifizierten Mustern und Aktionen. Er arbeitet auf einer zeilenweisen Basis und teilt jede Zeile in Felder auf.
awk-Syntax ist:
awk 'pattern { action }' input-file
Beispielsweise:
awk '/error/ {print $1}' /var/log/syslog
Dies druckt das erste Feld jeder Zeile, die „error.“ enthält. awk kann auch eingebaute Variablen wie NR (Anzahl der Datensätze) und NF (Anzahl der Felder) verwenden.
Erweiterte awk-Fähigkeiten umfassen:
- Mathematische Berechnungen auf Feldern
- Bedingte Anweisungen
- Eingebaute Funktionen zur Manipulation von Zeichenketten, Zahlen und Daten
- Kontrolle des Ausgabeformats
Dies macht awk geeignet für Datenextraktion, Berichterstattung und das Transformieren von Textausgaben. awk ist extrem leistungsstark, da es eine unabhängige Programmiersprache ist, die Ihnen viel Kontrolle als Linux-Befehl bietet.
13. sed – Stream Editor für das Filtern und Transformieren von Text
Der sed Befehl ermöglicht das Filtern und Transformieren von Text. Er kann Operationen wie Suchen/Ersetzen, Löschen, Transponieren und mehr durchführen. Im Gegensatz zu awk wurde sed jedoch für das Bearbeiten von Zeilen auf Basis einzelner Anweisungen entwickelt.
Hier ist die grundlegende Syntax:
sed options 'commands' input-file
Zum Beispiel:
sed 's/foo/bar/' file.txt
Dies ersetzt „foo“ durch „bar“ in file.txt.
Einige nützliche sed-Befehle:
s– Text suchen und ersetzen/pattern/d– Zeilen löschen, die einem Muster entsprechen10,20d– Zeilen 10-20 löschen1,3!d– Alle außer Zeilen 1-3 löschen
sed ist ideal für Aufgaben wie Massensuche/Ersetzung, selektives Zeilenlöschen und andere Operationen zur Textstrombearbeitung.
14. sort – Sortieren von Textdateizeilen
Wenn Sie mit viel Text oder Daten oder sogar großen Ausgaben anderer Befehle arbeiten, ist das Sortieren eine großartige Möglichkeit, die Dinge überschaubar zu machen. Der sort Befehl wird die Zeilen einer Textdatei alphabetisch oder numerisch sortieren.
Grundlegende Sortiersyntax:
sort [Optionen] [Datei]
Nützliche Sortieroptionen:
-n– Numerisch statt alphabetisch sortieren-r– Die Sortierreihenfolge umkehren-k– Basierend auf einem spezifischen Feld oder einer Spalte sortieren
Zum Beispiel:
sort -n grades.txt
Dies sortiert die Inhalte von grades.txt numerisch. sort ist praktisch, um die Inhalte von Dateien für eine lesbarere Ausgabe oder Analyse zu ordnen.
15. uniq – Berichten oder Auslassen wiederholter Zeilen
Der uniq-Befehl filtert doppelte angrenzende Zeilen aus der Eingabe. Dies wird oft in Verbindung mit Sortieren verwendet.
Grundlegende Syntax:
uniq [Optionen] [Eingabe]
Optionen:
-c– Eindeutige Zeilen mit der Anzahl der Vorkommen kennzeichnen.-d– Nur doppelte Zeilen anzeigen, keine einzigartigen.
Beispielweise:
sort data.txt | uniq
Dies wird alle doppelten Zeilen in data.txt nach der Sortierung entfernen. uniq gibt Ihnen Kontrolle über das Filtern wiederholten Textes.
16. diff – Vergleichen von Dateien Zeile für Zeile
Der diff Befehl vergleicht zwei Dateien Zeile für Zeile und druckt die Unterschiede aus. Er wird häufig verwendet, um Änderungen zwischen verschiedenen Versionen von Dateien anzuzeigen.
Syntax:
diff [Optionen] Datei1 Datei2
Optionen:
-b– Änderungen in Leerzeichen ignorieren.-B– Unterschiede direkt anzeigen, indem Änderungen hervorgehoben werden.-u– Ausgabe der Unterschiede mit drei Zeilen Kontext.
Zum Beispiel:
diff original.txt updated.txt
Dies gibt die Zeilen aus, die sich zwischen original.txt und updated.txt unterscheiden. diff ist unverzichtbar für den Vergleich von Revisionen von Textdateien und Quellcode.
17. wc – Zeilen-, Wort- und Bytezahlen drucken
Der wc (Wortzählung) Befehl gibt die Anzahl der Zeilen, Wörter und Bytes in einer Datei aus.
Syntax:
wc [options] [file]
Optionen:
-l– Nur die Zeilenanzahl ausdrucken.-w– Nur die Wortanzahl ausdrucken.-c– Nur die Byteanzahl ausdrucken.
Beispielsweise:
wc report.txt
Dieser Befehl gibt die Anzahl der Zeilen, Wörter und Bytes in report.txt aus.
Umleitungs-Befehle in Linux
Umleitungs-Befehle werden verwendet, um Eingabe- und Ausgabequellen in Linux zu steuern, sodass Sie Ausgabeströme an Dateien senden und anhängen, Eingaben aus Dateien nehmen, mehrere Befehle verbinden und Ausgaben auf mehrere Ziele aufteilen können.
18. > – Standardausgabe umleiten
Der > Umleitung-Operator leitet den Standardausgabestrom des Befehls in eine Datei um, anstatt auf das Terminal zu drucken. Vorhandene Inhalte der Datei werden überschrieben.
Zum Beispiel:
ls -l /home > homelist.txt
Dies wird ls -l ausführen, um den Inhalt des /home-Verzeichnisses aufzulisten.
Dann wird anstatt die Ausgabe auf das Terminal zu drucken, das Symbol > die Standardausgabe abfangen und in homelist.txt schreiben, wobei alle vorhandenen Dateiinhalte überschrieben werden.
Das Umleiten der Standardausgabe ist hilfreich, um Befehlsergebnisse in Dateien zu speichern für Speicherung, Debugging oder zum Verketten von Befehlen.
19. >> – Standardausgabe anhängen
Der >> Operator hängt die Standardausgabe eines Befehls an eine Datei an, ohne vorhandene Inhalte zu überschreiben.
Zum Beispiel:
tail /var/log/syslog >> logfile.txt
Dies wird die letzten 10 Zeilen der syslog Protokolldatei an das Ende der logfile.txt anhängen. Anders als >, fügt >> die Ausgabe hinzu, ohne den aktuellen Inhalt der logfile.txt zu löschen.
Anhängen ist hilfreich, um Befehlsausgaben an einem Ort zu sammeln, ohne vorhandene Daten zu verlieren.
20. < – Standard-Eingabe umleiten
Der Umleitungsoperator < verwendet den Inhalt einer Datei als Standard-Eingabe für einen Befehl, anstatt die Eingabe von der Tastatur zu nehmen.
Zum Beispiel:
wc -l < myfile.txt
Dies sendet den Inhalt von myfile.txt als Eingabe an den wc-Befehl, der die Zeilen in dieser Datei zählt, anstatt auf Tastatureingaben zu warten.
Die Umleitung der Eingabe ist nützlich für die Stapelverarbeitung von Dateien und die Automatisierung von Arbeitsabläufen.
21. | – Ausgabe an einen anderen Befehl weiterleiten
Der Pipe-Operator | leitet die Ausgabe eines Befehls als Eingabe an einen anderen Befehl weiter und verbindet sie miteinander.
Zum Beispiel:
ls -l | less
Dies leitet die Ausgabe von ls -l in den less-Befehl um, was das Durchblättern der Dateiliste ermöglicht.
Piping wird häufig verwendet, um Befehle zu verketten, bei denen die Ausgabe des einen die Eingabe des anderen speist. Dies ermöglicht den Aufbau komplexer Operationen aus kleineren, einzelzweckorientierten Programmen.
22. tee – Aus der Standardeingabe lesen und in die Standardausgabe und Dateien schreiben
Der tee-Befehl teilt die Standardeingabe in zwei Ströme auf.
Es schreibt die Eingabe in die Standardausgabe (zeigt die Ausgabe des Hauptbefehls), während gleichzeitig eine Kopie in einer Datei gespeichert wird.
Zum Beispiel:
cat file.txt | tee copy.txt
Dies zeigt den Inhalt von file.txt im Terminal an, während es gleichzeitig in copy.txt geschrieben wird.
tee unterscheidet sich vom Umleiten, bei dem Sie die Ausgabe nicht sehen, bis Sie die Datei öffnen, in die Sie die Ausgabe umgeleitet haben.
Archivbefehle
Archivierungsbefehle ermöglichen es Ihnen, mehrere Dateien und Verzeichnisse in komprimierte Archivdateien zu bündeln, um eine einfachere Portabilität und Speicherung zu ermöglichen. Häufige Archivformate in Linux umfassen .tar, .gz und .zip.
23. tar – Dateien in einem Archiv speichern und extrahieren
Der tar Befehl hilft Ihnen dabei, mit Tape-Archiv (.tar) Dateien zu arbeiten. Er ermöglicht es Ihnen, mehrere Dateien und Verzeichnisse in einer einzigen komprimierten .tar-Datei zu bündeln.
Syntax:
tar [options] filename
Nützliche tar Optionen:
-c– Erstellen Sie eine neue .tar-Archivdatei.-x– Dateien aus einem .tar-Archiv extrahieren.-f– Angeben des Archivdateinamens anstelle von stdin/stdout.-v– Ausführliche Ausgabe, die archivierte Dateien zeigt.-z– Archiv mit gzip komprimieren oder dekomprimieren.
Beispielweise:
tar -cvzf images.tar.gz /home/user/images
Dies erstellt ein gzip-komprimiertes tar-Archiv mit dem Namen images.tar.gz, das den Ordner /home/user/images enthält.
24. gzip – Dateien komprimieren oder erweitern
Der gzip-Befehl komprimiert Dateien unter Verwendung der LZ77-Codierung, um die Größe für die Speicherung oder Übertragung zu reduzieren. Mit gzip arbeitest du mit .gz-Dateien.
Syntax:
gzip [options] filename
Nützliche gzip-Optionen:
-c– Ausgabe auf stdout statt in Datei schreiben.-d– Datei dekomprimieren statt komprimieren.-r– Verzeichnisse rekursiv komprimieren.
Zum Beispiel:
gzip -cr documents/
Der obige Befehl komprimiert rekursiv den Dokumentenordner und gibt ihn auf stdout aus.
25. gunzip – Dateien dekomprimieren
Der Befehl gunzip wird zum Entpacken von .gz-Dateien verwendet.
Syntax:
gunzip filename.gz
Beispiel:
gunzip documents.tar.gz
Der obige Befehl wird die ursprünglichen unkomprimierten Inhalte von documents.tar.gz extrahieren.
26. zip – Paketieren und komprimieren von Dateien
Der zip-Befehl erstellt .zip-Archivdateien, die komprimierte Dateiinhalte enthalten.
Syntax:
zip [options] archive.zip filenames
Nützliche Zip-Optionen:
-r– Ein Verzeichnis rekursiv zippen.-e– Inhalte mit einem Passwort verschlüsseln.
Beispiel:
zip -re images.zip pictures
Dies verschlüsselt und komprimiert den Ordner Bilder in images.zip.
27. unzip – Dateien aus ZIP-Archiven extrahieren
Ähnlich wie gunzip extrahiert und entpackt der Befehl unzip Dateien aus .zip-Archiven.
Syntax:
unzip archive.zip
Beispiel:
unzip images.zip
Der obige Beispielbefehl extrahiert alle Dateien aus images.zip im aktuellen Verzeichnis.
Dateiübertragungsbefehle
Dateiübertragungsbefehle ermöglichen es Ihnen, Dateien über ein Netzwerk zwischen Systemen zu verschieben. Dies ist nützlich für das Kopieren von Dateien auf entfernte Server oder das Herunterladen von Inhalten aus dem Internet.
28. scp – Sicheres Kopieren von Dateien zwischen Hosts
Der scp (secure copy) Befehl kopiert Dateien zwischen Hosts über eine SSH-Verbindung. Alle Datenübertragungen sind zur Sicherheit verschlüsselt.
Die scp-Syntax kopiert Dateien von einem Quellpfad zu einem Ziel, das als user@host definiert ist:
scp source user@host:destination
Zum Beispiel:
scp image.jpg user@server:/uploads/
Dies kopiert sicher image.jpg in den /uploads Ordner auf dem Server als Benutzer.
scp funktioniert wie der cp Befehl, jedoch für die Übertragung von Dateien über das Netzwerk. Es nutzt SSH (Secure Shell) für den Datentransfer und bietet Verschlüsselung, um sicherzustellen, dass keine sensiblen Daten, wie Passwörter, im Netzwerk offengelegt werden. Die Authentifizierung erfolgt typischerweise über SSH-Schlüssel, obwohl auch Passwörter verwendet werden können. Dateien können sowohl von als auch zu entfernten Hosts kopiert werden.
29. rsync – Dateien zwischen Hosts synchronisieren
Das rsync Werkzeug synchronisiert Dateien zwischen zwei Standorten, während es den Datentransfer durch Delta-Kodierung minimiert. Dies beschleunigt die Synchronisation großer Verzeichnisbäume.
rsync-Syntax synchronisiert die Quelle mit dem Ziel:
rsync [options] source destination
Zum Beispiel:
rsync -ahv ~/documents user@server:/backups/
Der obige Beispielbefehl synchronisiert den Dokumentenordner rekursiv mit server:/backups/, wobei eine ausführliche, menschenlesbare Ausgabe angezeigt wird.
Nützliche rsync Optionen:
-a– Der Archivmodus synchronisiert rekursiv und bewahrt Berechtigungen, Zeiten usw.-h– Menschlich lesbare Ausgabe.-v– Ausführliche Ausgabe.
rsync ist ideal für das Synchronisieren von Dateien und Ordnern mit entfernten Systemen und hält die Dinge dezentral gesichert und sicher.
30. sftp – Sicheres Dateiübertragungsprogramm
Das Programm sftp ermöglicht interaktive Dateiübertragungen über SSH, ähnlich dem regulären FTP, jedoch verschlüsselt. Es kann Dateien zu/von entfernten Systemen übertragen.
sftp verbindet sich mit einem Host und akzeptiert Befehle wie:
sftp user@host
get remotefile localfile
put localfile remotefile
Dies ruft remotefile vom Server ab und kopiert localfile auf den Remote-Host.
sftp hat eine interaktive Shell zum Navigieren in entfernten Dateisystemen, zum Übertragen von Dateien und Verzeichnissen sowie zum Verwalten von Berechtigungen und Eigenschaften.
31. wget – Dateien aus dem Web abrufen
Das wget-Tool lädt Dateien über HTTP, HTTPS und FTP-Verbindungen herunter. Es ist nützlich, um Webressourcen direkt aus dem Terminal abzurufen.
Zum Beispiel:
wget https://example.com/file.iso
Dies lädt das file.iso-Abbild vom entfernten Server herunter.
Nützliche wget-Optionen:
-c– Unterbrochene Downloads fortsetzen.-r– Rekursiv herunterladen.-O– Unter spezifischem Dateinamen speichern.
wget ist ideal für das Skripten automatischer Downloads und das Spiegeln von Websites.
32. curl – Datenübertragung von oder zu einem Server
Der curl-Befehl überträgt Daten zu oder von einem Netzwerkserver unter Verwendung unterstützter Protokolle. Dazu gehören REST, HTTP, FTP und mehr.
Zum Beispiel:
curl -L https://example.com
Der obige Befehl ruft Daten von der HTTPS-URL ab und gibt sie aus.
Nützliche curl Optionen:
-o– Schreibe Ausgabe in Datei.-I– Zeige nur Antwort-Header an.-L– Folge Weiterleitungen.
curl ist darauf ausgelegt, Daten programmatisch über Netzwerke zu übertragen.
Befehle für Dateiberechtigungen
Dateiberechtigungsbefehle ermöglichen es Ihnen, Zugriffsrechte für Benutzer zu ändern. Dies umfasst das Festlegen von Lese-/Schreib-/Ausführungsberechtigungen, das Ändern des Eigentums und die Standarddateimodi.
33. chmod – Dateizugriffsrechte ändern
Der chmod-Befehl wird verwendet, um die Zugriffsberechtigungen oder Modi von Dateien und Verzeichnissen zu ändern. Die Berechtigungsmodi repräsentieren, wer die Datei lesen, schreiben oder ausführen kann.
Zum Beispiel:
chmod 755 file.txt
Es gibt drei Sätze von Berechtigungen—Besitzer, Gruppe und Öffentlichkeit. Berechtigungen werden mit numerischen Modi von 0 bis 7 festgelegt:
- 7 – lesen, schreiben und ausführen.
- 6 – lesen und schreiben.
- 4 – nur lesen.
- 0 – keine Berechtigung.
Dies setzt die Besitzerberechtigungen auf 7 (rwx), die Gruppe auf 5 (r-x) und die Öffentlichkeit auf 5 (r-x). Sie können auch Benutzer und Gruppen symbolisch referenzieren:
chmod g+w file.txt
Die g+w Syntax fügt die Schreibberechtigung für die Gruppe zur Datei hinzu.
Das Festlegen geeigneter Datei- und Verzeichnisberechtigungen ist entscheidend für die Linux-Sicherheit und die Zugriffskontrolle. chmod bietet Ihnen flexible Kontrolle, um Berechtigungen genau nach Bedarf zu konfigurieren.
34. chown – Besitzer und Gruppe der Datei ändern
Der chown Befehl ändert den Besitzer einer Datei oder eines Verzeichnisses. Der Besitz hat zwei Komponenten – den Benutzer, der der Besitzer ist, und die Gruppe, zu der er gehört.
Zum Beispiel:
chown john:developers file.txt
Der obige Beispielbefehl wird den Besitzerbenutzer auf „john“ und die Besitzergruppe auf „developers“ setzen.
Nur das Root-Superuser-Konto kann chown verwenden, um Dateibesitzer zu ändern. Es wird verwendet, um Berechtigungsprobleme zu beheben, indem der Besitzer und die Gruppe nach Bedarf geändert werden.
35. umask – Standarddateiberechtigungen festlegen
Der umask-Befehl steuert die Standardberechtigungen, die neu erstellten Dateien gegeben werden. Er nimmt eine oktale Maske als Eingabe, die von 666 für Dateien und 777 für Verzeichnisse subtrahiert.
Zum Beispiel:
umask 007
Neue Dateien werden standardmäßig die Berechtigungen 750 statt 666 haben, und neue Verzeichnisse 700 statt 777.
Das Festlegen eines umask ermöglicht es Ihnen, Standarddateiberechtigungen zu konfigurieren, anstatt auf Systemstandards zu vertrauen. Der umask-Befehl ist nützlich, um Berechtigungen für neue Dateien einzuschränken, ohne dass jemand manuell Einschränkungen hinzufügen muss.
Befehle zur Prozessverwaltung
Diese Befehle ermöglichen es Ihnen, Prozesse auf Ihrem Linux-System zu betrachten, zu überwachen und zu steuern. Dies ist nützlich, um die Ressourcennutzung zu identifizieren und sich fehlverhaltende Programme zu stoppen.
36. ps – Bericht eines Schnappschusses der aktuellen Prozesse
Der ps Befehl zeigt eine Momentaufnahme der aktuell laufenden Prozesse, einschließlich ihrer PID, TTY, stat, Startzeit usw. an.
Beispielweise:
ps aux
Dies zeigt jeden Prozess, der als alle Benutzer mit zusätzlichen Details wie CPU- und Speichernutzung ausgeführt wird.
Einige nützliche ps Optionen:
aux– Zeige Prozesse für alle Benutzer--forest– Baumstruktur von Eltern-/Kindprozessen anzeigen
ps gibt Ihnen Einblick, was derzeit auf Ihrem System läuft.
37. top – Anzeige von Linux-Prozessen
Der top Befehl zeigt Echtzeit-Linux-Prozessinformationen, einschließlich PID, Benutzer, CPU %, Speichernutzung, Betriebszeit und mehr. Anders als ps, aktualisiert er die Anzeige dynamisch, um die aktuelle Nutzung widerzuspiegeln.
Zum Beispiel:
top -u mysql
Der obige Befehl überwacht Prozesse nur für den „mysql“-Benutzer. Er wird sehr hilfreich bei der Identifizierung ressourcenintensiver Programme.
38. htop – Interaktiver Prozessbetrachter
Der htop Befehl ist ein interaktiver Prozessbetrachter, der den top Befehl ersetzt. Er zeigt Systemprozesse zusammen mit CPU-/Speicher-/Swap-Nutzungsdiagrammen, ermöglicht das Sortieren nach Spalten, das Beenden von Programmen und mehr.
Geben Sie einfach htop in der Befehlszeile ein, um Ihre Prozesse anzuzeigen.
htop verfügt über verbesserte UI-Elemente mit Farben, Scrollen und Mausunterstützung für eine einfachere Navigation im Vergleich zu top. Hervorragend geeignet zur Untersuchung von Prozessen.
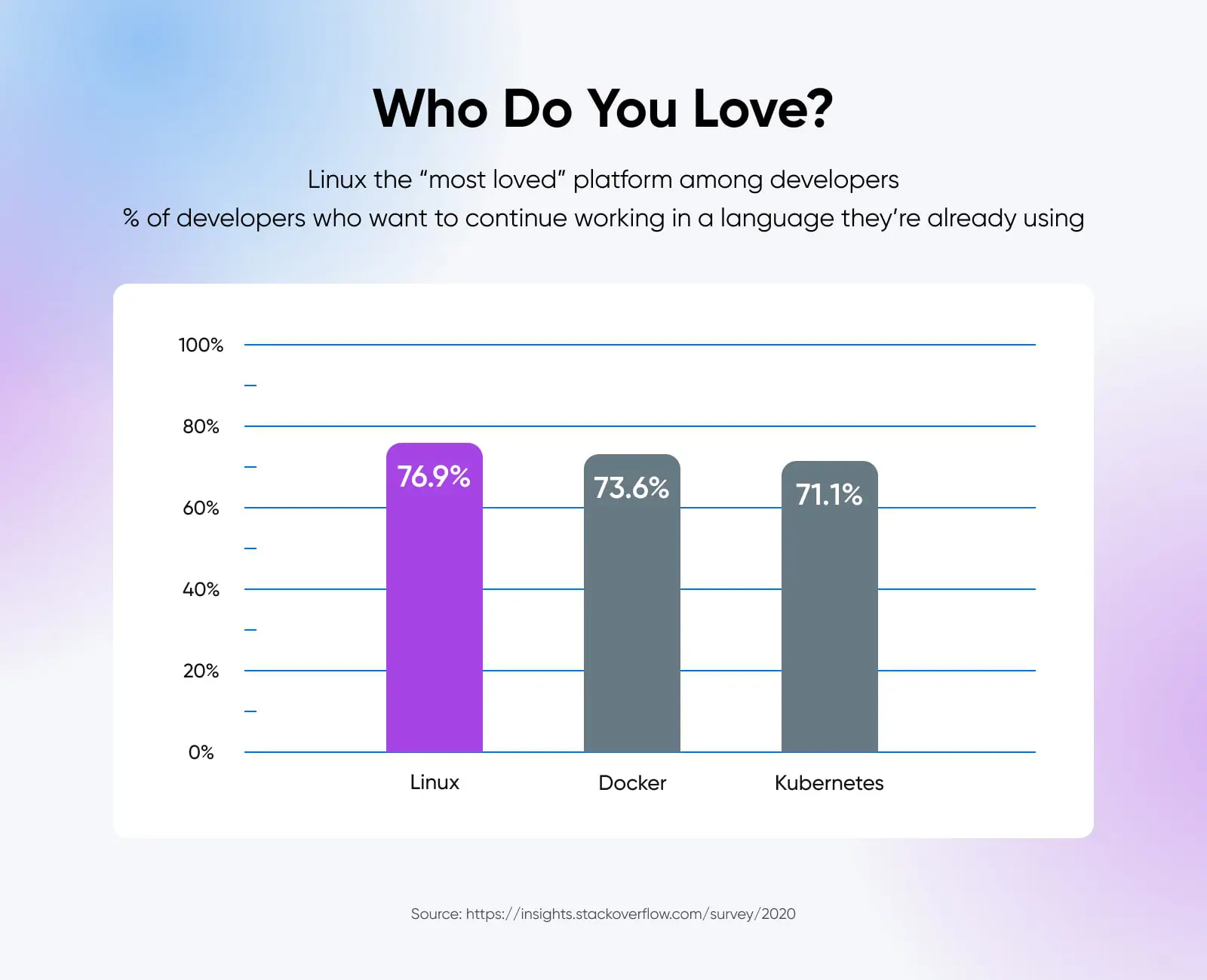
39. kill – Ein Signal an einen Prozess senden
Der kill-Befehl sendet ein Signal an einen Prozess, um ihn zu beenden oder zu töten. Signale ermöglichen ein sanftes Herunterfahren, wenn der Prozess sie verarbeitet.
Beispielsweise:
kill -15 12345
Der obige Befehl sendet das Signal SIGTERM (15), um den Prozess mit der PID 12345 sanft zu stoppen.
40. pkill – Ein Signal an einen Prozess basierend auf dem Namen senden
Der pkill Befehl beendet Prozesse nach Namen anstatt nach PID. Das kann einfacher sein, als zuerst die PID zu finden.
Zum Beispiel:
pkill -9 firefox
Dies stoppt alle Firefox-Prozesse mit SIGKILL (9) zwangsweise. pkill zielt auf Prozesse ab, indem es nach Namen, Benutzer und anderen Kriterien anstelle der PID sucht.
41. nohup – Führen Sie einen Befehl aus, der gegen Aufhängungen immun ist
Der nohup Befehl führt Prozesse aus, die gegen Hänger immun sind, sodass sie weiterlaufen, wenn Sie sich abmelden oder die Verbindung getrennt wird.
Zum Beispiel:
nohup python script.py &
Das oben genannte Beispielkommando wird script.py im Hintergrund losgelöst und immun gegen Aufhängungen starten. nohup wird allgemein verwendet, um dauerhafte Hintergrunddämonen und -dienste zu starten.
Leistungsüberwachungsbefehle
Diese Befehle liefern wertvolle Systemleistungsstatistiken, um die Ressourcennutzung zu analysieren, Engpässe zu identifizieren und die Effizienz zu optimieren.
42. vmstat – Bericht Virtuelle Speicherstatistiken
Der Befehl vmstat gibt detaillierte Berichte über Speicher, Swap, I/O und CPU-Aktivität aus. Dies umfasst Kennzahlen wie verwendeter/freier Speicher, Swap ein/aus, gelesene/geschriebene Festplattenblöcke und CPU-Zeit, die für Prozesse/Leerlauf aufgewendet wurde.
Zum Beispiel:
vmstat 5
Weitere nützliche vmstat-Optionen:
-a– Zeige aktiven und inaktiven Speicher an-s– Zeige Ereigniszähler und Speicherstatistiken an-S– Ausgabe in KB anstelle von Blöcken5– Ausgabe wird alle 5 Sekunden aktualisiert.
Das oben genannte Beispiel gibt Speicher- und CPU-Daten alle 5 Sekunden aus, bis es unterbrochen wird, was für die Überwachung der Live-Systemleistung nützlich ist.
43. iostat – Bericht CPU und I/O Statistiken
Der Befehl iostat überwacht und zeigt die CPU-Auslastung sowie die Festplatten-I/O-Metriken an. Dies umfasst CPU-Last, IOPS, Lese-/Schreib-Durchsatz und mehr.
Zum Beispiel:
iostat -d -p sda 5
Einige iostat Optionen:
-c– CPU-Auslastungsinformationen anzeigen-t– Zeitstempel für jeden Bericht drucken-x– Erweiterte Statistiken wie Dienstzeiten und Wartezeiten anzeigen-d– Detaillierte Statistiken pro Festplatte/Partition statt Gesamtsummen anzeigen-p– Statistiken für spezifische Festplattengeräte anzeigen
Dies zeigt detaillierte I/O-Statistiken pro Gerät für sda alle 5 Sekunden.
iostat hilft dabei, die Leistung des Festplattensubsystems zu analysieren und Hardware-Engpässe zu identifizieren.
44. free – Anzeige der Menge an freiem und verwendetem Speicher
Der free Befehl zeigt die Gesamtmenge, die verwendete und die freie Menge an physischem und Swap-Speicher im System an. Dies gibt eine Übersicht über den verfügbaren Speicher.
Beispielweise:
free -h
Einige Optionen für den Befehl free:
-b– Ausgabe in Bytes anzeigen-k– Zeige Ausgabe in KB statt standardmäßig in Bytes-m– Zeige Ausgabe in MB statt in Bytes-h– Statistiken im benutzerfreundlichen Format wie GB, MB statt in Bytes drucken.
Dies druckt Speicherstatistiken in einem menschenlesbaren Format (GB, MB usw.). Es ist nützlich, wenn Sie eine schnelle Übersicht über die Speicherkapazität wünschen.
45. df – Bericht zur Nutzung des Festplattenspeicherplatzes im Dateisystem
Der Befehl df zeigt die Speichernutzung für Dateisysteme an. Er zeigt den Dateisystemnamen, den gesamten/genutzten/verfügbaren Speicherplatz und die Kapazität.
Beispielsweise:
df -h
Der oben genannte Befehl gibt die Festplattennutzung in einem menschenlesbaren Format aus. Sie können ihn auch ohne Argumente ausführen, um dieselben Daten in Blockgrößen zu erhalten.
46. sar – Sammeln und Berichten von Systemaktivitäten
Das sar Werkzeug sammelt und protokolliert Informationen über die Systemaktivität in Bezug auf CPU, Speicher, I/O, Netzwerk und mehr über die Zeit. Diese Daten können analysiert werden, um Leistungsprobleme zu identifizieren.
Beispielsweise:
sar -u 5 60
Diese Probe misst die CPU-Auslastung alle 5 Sekunden für eine Dauer von 60 Proben.
sar liefert detaillierte historische Systemleistungsdaten, die in Echtzeit-Tools nicht verfügbar sind.
Benutzerverwaltungsbefehle
Bei der Verwendung von Mehrbenutzersystemen benötigen Sie möglicherweise Befehle, die Ihnen helfen, Benutzer und Gruppen für Zugriffskontrolle und Berechtigungen zu verwalten. Lassen Sie uns diese Befehle hier behandeln.
47. useradd – Einen neuen Benutzer erstellen
Der Befehl useradd erstellt ein neues Benutzerkonto und ein Home-Verzeichnis. Er legt die UID, Gruppe, Shell und andere Standardwerte des neuen Benutzers fest.
Zum Beispiel:
useradd -m john
Nützliche useradd Optionen:
-m– Erstellen Sie das Home-Verzeichnis des Benutzers.-g– Geben Sie die primäre Gruppe anstelle der Standardgruppe an.-s– Legen Sie die Anmelde-Shell des Benutzers fest.
Der obige Befehl wird einen neuen Benutzer, „john“, mit einer generierten UID und einem erstellten Home-Ordner unter /home/john erstellen.
48. usermod – Ein Benutzerkonto ändern
Der Befehl usermod ändert die Einstellungen eines bestehenden Benutzerkontos. Dies kann den Benutzernamen, das Home-Verzeichnis, die Shell, die Gruppe, das Ablaufdatum usw. ändern.
Zum Beispiel:
usermod -aG developers john
Mit diesem Befehl fügen Sie einen Benutzer john einer zusätzlichen Gruppe—„developers“ hinzu. Das -a ergänzt die bestehende Liste von Gruppen, zu denen der Benutzer hinzugefügt wird.
49. userdel – Ein Benutzerkonto löschen
Der Befehl userdel löscht ein Benutzerkonto, das Home-Verzeichnis und den Mail-Spool.
Zum Beispiel:
userdel -rf john
Nützliche userdel-Optionen:
-r– Entfernen Sie das Home-Verzeichnis des Benutzers und den Mail-Spool.-f– Löschung erzwingen, auch wenn der Benutzer noch eingeloggt ist.
Dies erzwingt die Entfernung des Benutzers „john“, wobei zugehörige Dateien gelöscht werden.
Das Angeben von Optionen wie -r und -f mit userdel stellt sicher, dass das Benutzerkonto vollständig gelöscht wird, auch wenn der Benutzer eingeloggt ist oder aktive Prozesse hat.
50. groupadd – Eine Gruppe hinzufügen
Der Befehl groupadd erstellt eine neue Benutzergruppe. Gruppen repräsentieren Teams oder Rollen für Berechtigungszwecke.
Zum Beispiel:
groupadd -r sysadmin
Nützliche groupadd-Optionen:
-r– Erstellen Sie eine Systemgruppe, die für Kernsystemfunktionen verwendet wird.-g– Geben Sie die GID der neuen Gruppe an, anstatt die nächste verfügbare zu verwenden.
Der obige Befehl erstellt eine neue „sysadmin“-Gruppe mit Systemprivilegien. Bei der Erstellung neuer Gruppen helfen die Optionen -r oder -g dabei, sie korrekt einzurichten.
51. passwd – Aktualisierung der Authentifizierungs-Token des Benutzers
Der passwd Befehl setzt oder aktualisiert das Authentifizierungspasswort/-tokens eines Benutzers. Dies ermöglicht das Ändern Ihres Anmeldepassworts.
Zum Beispiel:
passwd john
Dies fordert den Benutzer „john“ auf, interaktiv ein neues Passwort einzugeben. Wenn Sie das Passwort für ein Konto verloren haben, möchten Sie sich möglicherweise mit sudo- oder su-Rechten bei Linux anmelden und das Passwort auf die gleiche Weise ändern.
Networking-Befehle
Diese Befehle werden zur Überwachung von Verbindungen, zur Fehlerbehebung bei Netzwerkproblemen, zum Routing, DNS-Abfragen und zur Schnittstellenkonfiguration verwendet.
52. ping – ICMP ECHO_REQUEST an Netzwerkhosts senden
Der ping Befehl überprüft die Verbindung zu einem entfernten Host, indem er ICMP-Echoanforderungspakete sendet und auf Echoantworten hört.
Zum Beispiel:
ping google.comPING google.com (142.251.42.78): 56 Datenbytes64 Bytes von 142.251.42.78: icmp_seq=0 ttl=112 Zeit=8.590 ms64 Bytes von 142.251.42.78: icmp_seq=1 ttl=112 Zeit=12.486 ms64 Bytes von 142.251.42.78: icmp_seq=2 ttl=112 Zeit=12.085 ms64 Bytes von 142.251.42.78: icmp_seq=3 ttl=112 Zeit=10.866 ms--- google.com Ping Statistik ---4 Pakete übertragen, 4 Pakete empfangen, 0.0% PaketverlustHin- und Rückfahrt min/durchschn./max/stdabw = 8.590/11.007/12.486/1.518 ms
Nützliche Ping-Optionen:
-c [count]– Begrenze die gesendeten Pakete.-i [interval]– Warte intervall Sekunden zwischen den Pings.
Mit dem obigen Befehl pingen Sie google.com und es werden Statistiken zur Hin- und Rückfahrt ausgegeben, die die Konnektivität und Latenz anzeigen. Allgemein wird ping verwendet, um zu überprüfen, ob ein System, mit dem Sie sich verbinden möchten, aktiv und mit dem Netzwerk verbunden ist.
53. ifconfig – Netzwerkschnittstellen konfigurieren
Der Befehl ifconfig zeigt Netzwerkschnittstelleneinstellungen an und konfiguriert diese, einschließlich IP-Adresse, Netzmaske, Broadcast, MTU und Hardware-MAC-Adresse.
Zum Beispiel:
ifconfigeth0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500inet 10.0.2.15 netmask 255.255.255.0 broadcast 10.0.2.255inet6 fe80::a00:27ff:fe1e:ef1d prefixlen 64 scopeid 0x20<link>ether 08:00:27:1e:ef:1d txqueuelen 1000 (Ethernet)RX Pakete 23955654 Bytes 16426961213 (15.3 GiB)RX Fehler 0 verloren 0 Überläufe 0 Rahmen 0TX Pakete 12432322 Bytes 8710937057 (8.1 GiB)TX Fehler 0 verloren 0 Überläufe 0 Träger 0 Kollisionen 0
Das Ausführen von ifconfig ohne weitere Argumente liefert eine Liste aller verfügbaren Netzwerkschnittstellen zur Nutzung, zusammen mit IP und zusätzlichen Netzwerkinformationen. ifconfig kann auch verwendet werden, um Adressen festzulegen, Schnittstellen zu aktivieren/deaktivieren und Optionen zu ändern.
54. netstat – Netzwerkstatistiken
Der Befehl netstat zeigt Ihnen die Netzwerkverbindungen, Routingtabellen, Schnittstellenstatistiken, Maskierungsverbindungen und Multicast-Mitgliedschaften.
Zum Beispiel:
netstat -pt tcp
Dieser Befehl gibt alle aktiven TCP-Verbindungen und die Prozesse aus, die sie verwenden.
55. ss – Socket-Statistiken
Der ss Befehl gibt Socket-Statistikinformationen ähnlich wie netstat aus. Er kann offene TCP- und UDP-Sockets, Senden/Empfangen-Puffergrößen und mehr anzeigen.
Zum Beispiel:
ss -t -a
Dies druckt alle offenen TCP-Sockets. Effizienter als netstat.
56. Traceroute – Trace Route To Host
Der traceroute Befehl gibt die Route aus, die Pakete zu einem Netzwerkhost nehmen, und zeigt jeden Sprung auf dem Weg sowie die Übertragungszeiten. Nützlich für die Netzwerkfehlerbehebung.
Zum Beispiel:
traceroute google.com
Dies verfolgt den Weg, um google.com zu erreichen und gibt jeden Netzwerksprung aus.
57. dig - DNS Lookup
Der dig Befehl führt DNS-Suchen durch und gibt Informationen zu DNS-Einträgen für eine Domain zurück.
Zum Beispiel:
dig google.com; <<>> DiG 9.10.6 <<>> google.com;; global options: +cmd;; Got answer:;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 60290;; flags: qr rd ra; QUERY: 1, ANSWER: 1, AUTHORITY: 0, ADDITIONAL: 1;; OPT PSEUDOSECTION:; EDNS: version: 0, flags:; udp: 1280;; QUESTION SECTION:;google.com. IN A;; ANSWER SECTION:google.com. 220 IN A 142.251.42.78;; Abfragezeit: 6 msec;; SERVER: 2405:201:2:e17b::c0a8:1d01#53(2405:201:2:e17b::c0a8:1d01);; WANN: Mi Nov 15 01:36:16 IST 2023;; MSG GRÖßE empf.: 55
Diese Abfragen DNS-Server nach Einträgen, die sich auf google.com beziehen und druckt Details.
58. nslookup – Abfrage von Internet-Namensservern interaktiv
Der Befehl nslookup fragt DNS-Server interaktiv ab, um Namensauflösungen durchzuführen oder DNS-Einträge anzuzeigen.
Es öffnet eine interaktive Shell, die es Ihnen ermöglicht, manuell Hostnamen zu suchen, IP-Adressen rückwärts zu ermitteln, DNS-Eintragstypen zu finden und mehr.
Zum Beispiel einige häufige Verwendungen von nslookup. Geben Sie nslookup in Ihre Kommandozeile ein:
nslookup
Als nächstes setzen wir Googles 8.8.8.8 DNS-Server für Suchanfragen.
> server 8.8.8.8
Jetzt fragen wir den A-Eintrag von stackoverflow.com ab, um seine IP-Adresse zu finden.
> set type=A> stackoverflow.comServer: 8.8.8.8Address: 8.8.8.8#53Nicht autoritative Antwort:Name: stackoverflow.comAdresse: 104.18.32.7Name: stackoverflow.comAdresse: 172.64.155.249
Jetzt finden wir die MX-Einträge für github.com, um seine Mailserver zu sehen.
> set type=MX> github.comServer: 8.8.8.8Address: 8.8.8.8#53Nicht autoritative Antwort:github.com Mail-Austauscher = 1 aspmx.l.google.com.github.com Mail-Austauscher = 5 alt1.aspmx.l.google.com.github.com Mail-Austauscher = 5 alt2.aspmx.l.google.com.github.com Mail-Austauscher = 10 alt3.aspmx.l.google.com.github.com Mail-Austauscher = 10 alt4.aspmx.l.google.com.
Die interaktiven Abfragen machen nslookup sehr nützlich zum Erkunden von DNS und zur Fehlerbehebung bei Problemen mit der Namensauflösung.
59. iptables – IPv4-Paketfilterung und NAT
Der Befehl iptables ermöglicht das Konfigurieren von Linux-Netfilter-Firewallregeln, um Netzwerkpakete zu filtern und zu verarbeiten. Er legt Richtlinien und Regeln fest, wie das System verschiedene Arten von eingehenden und ausgehenden Verbindungen und Datenverkehr behandeln wird.
Zum Beispiel:
iptables -A INPUT -s 192.168.1.10 -j DROP
Der obige Befehl wird alle Eingaben von der IP 192.168.1.10 blockieren.
iptables bietet eine leistungsstarke Kontrolle über die Linux-Kernel-Firewall, um Routing, NAT, Paketfilterung und andere Verkehrskontrollen zu handhaben. Es ist ein kritisches Werkzeug zur Sicherung von Linux-Servern.
60. ip – Netzwerkgeräte und Routing verwalten
Der ip-Befehl ermöglicht das Verwalten und Überwachen verschiedener netzwerkgerätebezogener Aktivitäten wie das Zuweisen von IP-Adressen, das Einrichten von Subnetzen, das Anzeigen von Linkdetails und das Konfigurieren von Routing-Optionen.
Zum Beispiel:
ip link show1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:002: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP mode DEFAULT group default qlen 1000link/ether 08:00:27:8a:5c:04 brd ff:ff:ff:ff:ff:ff
Der obige Befehl zeigt alle Netzwerkschnittstellen, ihren Status und weitere Informationen.
Dieser Befehl zielt darauf ab, ifconfig durch eine modernere Linux-Netzwerkverwaltung zu ersetzen. ip kann Netzwerkgeräte, Routingtabellen und andere Netzwerkstapel-Einstellungen steuern.
Paketverwaltungsbefehle
Paketmanager ermöglichen eine einfache Installation, Aktualisierung und Entfernung von Software auf Linux-Distributionen. Beliebte Paketmanager sind APT, YUM, DNF, Pacman und Zypper.
61. apt – Debian/Ubuntu Paketmanager
Der apt Befehl verwaltet Pakete auf Debian/Ubuntu-Systemen mit dem APT-Repository. Er ermöglicht das Installieren, Aktualisieren und Entfernen von Paketen.
Beispielweise:
apt update
Dieser Befehl holt die neuesten Paketversionen und Metadaten aus den Repositorien.
apt install nginx
Sie können das nginx-Paket aus den konfigurierten APT-Repositories mit dem oben genannten Befehl installieren.
apt upgrade
Und dieser Befehl aktualisiert Pakete und Abhängigkeiten auf neuere Versionen.
APT erleichtert die Installation von Software, indem es Pakete aus Repositories abruft.
62. pacman – Arch Linux Paketmanager
pacman verwaltet Pakete auf Arch Linux aus dem Arch User Repository. Es kann Pakete installieren, aktualisieren und entfernen.
Zum Beispiel:
pacman -S nmap
Dies installiert das nmap-Paket aus den konfigurierten Repositories.
pacman -Syu
Dies synchronisiert mit Repositories und aktualisiert alle Pakete.
pacman hält Arch Linux aktuell und ermöglicht eine einfache Verwaltung von Paketen.
63. dnf – Fedora Paketmanager
dnf installiert, aktualisiert und entfernt Pakete auf Fedora Linux-Distributionen, die RPM-Pakete verwenden. Es ersetzt Yum als den nächsten Generationen-Paketmanager.
Zum Beispiel:
dnf install util-linux
Dies installiert das util-linux Paket.
dnf upgrade
Dies aktualisiert alle installierten Pakete auf die neuesten Versionen.
dnf macht das Paketmanagement von Fedora schnell und effizient.
64. yum – Red Hat Paketmanager
yum verwaltet Pakete auf RHEL und CentOS Linux-Distributionen mit RPM-Paketen. Es holt aus Yum-Repositories, um zu installieren und zu aktualisieren.
Beispielweise:
yum update
Dies aktualisiert alle installierten Pakete auf die neuesten Versionen.
yum install httpd
Der obige Befehl installiert das Apache httpd-Paket. yum war der wichtigste Paketmanager, um Red Hat-Distributionen aktuell zu halten.
65. zypper – OpenSUSE Paketmanager
zypper verwaltet Pakete auf SUSE/openSUSE Linux. Es kann Repositories hinzufügen, suchen, installieren und Pakete aktualisieren.
Zum Beispiel:
zypper refresh
Der Aktualisierungsbefehl für zypper aktualisiert die Repository-Metadaten aus hinzugefügten Repositories.
zypper install python
Dies installiert das Python-Paket aus konfigurierten Repositories. zypper macht das Paketmanagement-Erlebnis mühelos auf SUSE/openSUSE-Systemen.
66. flatpak – Flatpak-Anwendungspaketmanager
Der Befehl flatpak hilft Ihnen, Flatpak-Anwendungen und -Laufzeiten zu verwalten. flatpak ermöglicht die verteilte Bereitstellung von Desktopanwendungen in einer Sandbox über Linux.
Beispielweise:
flatpak install flathub org.libreoffice.LibreOffice
Beispielsweise wird der obige Befehl LibreOffice aus dem Flathub-Repository installieren.
flatpak run org.libreoffice.LibreOffice
Und diese startet die sandboxed LibreOffice Flatpak-Anwendung. flatpak bietet ein zentrales, distributionsübergreifendes Linux-Anwendungsrepository, sodass Sie nicht mehr auf Pakete beschränkt sind, die in der Paketbibliothek einer spezifischen Distribution verfügbar sind.
67. appimage – AppImage Anwendungspaket-Manager
AppImage Pakete sind eigenständige Anwendungen, die auf den meisten Linux-Distributionen laufen. Der Befehl appimage führt vorhandene AppImages aus.
Zum Beispiel:
chmod +x myapp.AppImage./myapp.AppImage
Dies ermöglicht das direkte Ausführen der AppImage-Binärdatei.
AppImages ermöglichen die Bereitstellung von Anwendungen ohne systemweite Installation. Denken Sie daran wie an kleine Container, die alle Dateien enthalten, um die App ohne zu viele externe Abhängigkeiten auszuführen.
68. snap – Snappy Application Package Manager
Der snap Befehl verwaltet Snaps—containerisierte Softwarepakete. Snaps aktualisieren sich automatisch und funktionieren ähnlich wie Flatpak auf verschiedenen Linux-Distributionen.
Zum Beispiel:
snap install vlc
Dieser einfache Befehl installiert den VLC-Media-Player-Snap.
snap run vlc
Nach der Installation können Sie snap verwenden, um Pakete auszuführen, die über snap installiert wurden, indem Sie den oben genannten Befehl verwenden. Snaps isolieren Apps vom Basissystem für Portabilität und ermöglichen sauberere Installationen.
Systeminformationsbefehle
Diese Befehle ermöglichen es Ihnen, Details über Ihre Linux-Systemhardware, den Kernel, Distributionen, Hostnamen, Verfügbarkeit und mehr anzuzeigen.
69. uname – Systeminformationen drucken
Der uname Befehl zeigt detaillierte Informationen über den Linux-Systemkern, die Hardwarearchitektur, den Hostnamen und das Betriebssystem an. Dies umfasst Versionsnummern und Maschineninformationen.
Zum Beispiel:
uname -aLinux hostname 5.4.0-48-generic x86_64 GNU/Linux
uname ist nützlich, um diese Kernsystemdetails abzufragen. Einige Optionen umfassen:
-a– Zeige alle verfügbaren Systeminformationen an-r– Zeige nur die Kernel-Release-Nummer an
Der obige Befehl hat erweiterte Systeminformationen ausgegeben, einschließlich Kernel-Name/Version, Hardware-Architektur, Hostnamen und Betriebssystem.
uname -r
Dies wird nur die Kernel-Release-Nummer ausdrucken. Der uname Befehl zeigt Details über die Kernkomponenten Ihres Linux-Systems.
70. Hostname – Anzeigen oder festlegen des System-Hostnamens
Der Befehl hostname druckt oder setzt den Hostnamen-Identifikator für Ihr Linux-System im Netzwerk. Ohne Argumente wird der aktuelle Hostname angezeigt. Durch die Eingabe eines Namens wird der Hostname aktualisiert.
Zum Beispiel:
hostnamelinuxserver
Dies druckt linuxserver — den konfigurierten System-Hostname.
hostname UbuntuServer
hostnames identifizieren Systeme in einem Netzwerk. hostname ruft den Identifizierungsnamen Ihres Systems im Netzwerk ab oder konfiguriert diesen. Der zweite Befehl hilft Ihnen dabei, den lokalen Hostnamen in UbuntuServer zu ändern.
71. Uptime – Wie lange das System bereits läuft
Der uptime Befehl zeigt, wie lange das Linux-System seit dem letzten Neustart läuft. Er gibt die Betriebszeit und die aktuelle Zeit aus.
Führen Sie einfach den folgenden Befehl aus, um Ihre System-Verfügbarkeitsdaten zu erhalten:
uptime23:51:26 up 2 Tage, 4:12, 1 Benutzer, Lastdurchschnitt: 0.00, 0.01, 0.05
Dies zeigt die Systemlaufzeit an, wie lange das System seit dem letzten Neustart in Betrieb ist.
72. whoami – Aktive Benutzer-ID drucken
Der whoami Befehl gibt den effektiven Benutzernamen des aktuell in das System eingeloggten Benutzers aus. Er zeigt die Privilegienstufe an, auf der Sie arbeiten.
Geben Sie den Befehl in Ihrem Terminal ein, um die ID zu erhalten:
whoamijohn
Dies gibt den effektiven Benutzernamen aus, unter dem der aktuelle Benutzer angemeldet ist und operiert, und ist nützlich in Skripten oder Diagnosen, um zu identifizieren, als welcher Benutzerkonto Aktionen durchgeführt werden.
73. id – Echte und effektive Benutzer- und Gruppen-IDs drucken
Der id-Befehl gibt detaillierte Benutzer- und Gruppeninformationen über die effektiven IDs und Namen des aktuellen Benutzers aus. Dies beinhaltet:
- Tatsächliche Benutzer-ID und Name.
- Effektive Benutzer-ID und Name.
- Tatsächliche Gruppen-ID und Name.
- Effektive Gruppen-ID und Name.
Um den Befehl id zu verwenden, geben Sie einfach ein:
iduid=1000(john) gid=1000(john) groups=1000(john),10(wheel),998(developers)
Der Befehl id gibt die tatsächlichen und effektiven Benutzer- und Gruppen-IDs des aktuellen Benutzers aus. id zeigt Benutzer- und Gruppendetails an, die nützlich sind, um Dateizugriffsberechtigungen zu bestimmen.
74. lscpu – CPU-Architekturinformationen anzeigen
Der Befehl lscpu zeigt detaillierte Informationen zur CPU-Architektur, einschließlich:
- Anzahl der CPU-Kerne
- Anzahl der Sockel
- Modellname
- Cache-Größen
- CPU-Frequenz
- Adressgrößen
Um den Befehl lscpu zu verwenden, geben Sie einfach ein:
lscpuArchitektur: x86_64CPU Betriebsmodus(se): 32-bit, 64-bitByte-Reihenfolge: Little EndianCPU(s): 16Online CPU(s) Liste: 0-15
lscpu liefert Details zur CPU-Architektur wie die Anzahl der Kerne, Sockel, Modellname, Caches und mehr.
75. lsblk – Auflisten von Blockgeräten
Der Befehl lsblk listet Informationen über alle verfügbaren Blockgeräte auf, einschließlich lokaler Festplatten, Partitionen und logischer Volumes. Die Ausgabe umfasst Gerätenamen, Bezeichnungen, Größen und Einhängepunkte.
lsblkNAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINTsda 8:0 0 1.8T 0 disk|-sda1 8:1 0 512M 0 part /boot|-sda2 8:2 0 16M 0 part`-sda5 8:5 0 1.8T 0 part`-lvm1 254:0 0 1.8T 0 lvm /
lsblk listet alle Blockgeräte auf, einschließlich Festplatten, Partitionen und logischen Volumes. Gibt einen Überblick über Speichergeräte.
76. lsmod – Zeigen Sie den Status der Module im Linux-Kernel an
Der lsmod Befehl listet aktuell geladene Kernel-Module wie Gerätetreiber auf. Dies umfasst Networking, Speicherung und andere hardwarebezogene Module, die vom Linux-Kernel verwendet werden, um mit internen und externen Geräten zu kommunizieren.
lsmodModul Größe Verwendet vonipv6 406206 27evdev 17700 0crct10dif_pclmul 16384 1crc32_pclmul 16384 0ghash_clmulni_intel 16384 0aesni_intel 399871 0aes_x86_64 20274 1 aesni_intel
Wie Sie sehen können, listet es die derzeit geladenen Kernelmodule wie Gerätetreiber auf. In diesem Fall zeigt es die Verwendung von Netzwerk-, Eingabe-, Kryptografie- und Verschlüsselungsmodulen.
77. dmesg – Drucke oder steuere den Kernel-Ringpuffer
Der dmesg Befehl gibt Nachrichten aus dem Kernel-Ringpuffer aus. Dies umfasst wesentliche Systemereignisse, die vom Kernel während des Startvorgangs und des Betriebs aufgezeichnet wurden.
dmesg | grep -i error[ 12.345678] Fehler beim Empfang der gebündelten Leseantwort: -110[ 23.456789] tplink_mdio 0000:03:00.0: Direktes Firmware-Laden für tplink-mdio/leap_p8_v1_0.bin fehlgeschlagen mit Fehler -2[ 40.567890] iwlwifi 0000:09:00.0: Direktes Firmware-Laden für iwlwifi-ty-a0-gf-a0-59.ucode fehlgeschlagen mit Fehler -2
Das Greppen nach „error“ zeigt Probleme beim Laden spezifischer Firmware. Dies druckt gepufferte Kernel-Protokollnachrichten, einschließlich Systemereignissen wie Start, Fehler, Warnungen usw.
Systemverwaltungsbefehle
Systemadministratorbefehle helfen Ihnen dabei, Programme als andere Benutzer auszuführen, das System herunterzufahren oder neu zu starten und Init-Systeme sowie Dienste zu verwalten.
78. sudo – Führen Sie einen Befehl als anderer Benutzer aus
Der Befehl sudo ermöglicht es Ihnen, Befehle als ein anderer Benutzer, typischerweise der Superuser, auszuführen. Nach der Eingabe des sudo-Befehls werden Sie zur Eingabe Ihres Passworts aufgefordert, um sich zu authentifizieren.
Dies bietet erweiterten Zugriff für Aufgaben wie das Installieren von Paketen, das Bearbeiten von Systemdateien, das Verwalten von Diensten usw.
Beispielsweise:
sudo adduser bob[sudo] password for john:
Benutzer ‚bob‘ wurde dem System hinzugefügt.
Dies verwendet sudo, um einen neuen Benutzer, ‚bob‘, zu erstellen. Normale Benutzer können in der Regel ohne sudo keine Benutzer hinzufügen.
79. su – Benutzer-ID ändern oder Superuser werden
Der Befehl su ermöglicht es Ihnen, zu einem anderen Benutzerkonto zu wechseln, einschließlich des Superusers. Sie müssen das Passwort des Zielbenutzers angeben, um sich zu authentifizieren. Dies ermöglicht direkten Zugriff, um Befehle in der Umgebung eines anderen Benutzers auszuführen.
Zum Beispiel:
su bobKennwort:bob@linux:~$
Nach der Eingabe des Passworts von bob wechselt dieser Befehl den aktuellen Benutzer zu dem Benutzer ‘bob’. Die Shell-Aufforderung zeigt den neuen Benutzer an.
80. shutdown – Linux herunterfahren oder neu starten
Der Befehl shutdown plant das Ausschalten, Anhalten oder Neustarten des Systems nach einem festgelegten Timer oder sofort ein. Es ist erforderlich, um Mehrbenutzer-Linux-Systeme sicher neu zu starten oder herunterzufahren.
Zum Beispiel:
shutdown -r nowBroadcast message from root@linux Fri 2023-01-20 18:12:37 CST:Das System wird jetzt neu gestartet!
Dies startet das System sofort neu und warnt die Benutzer.
81. Neustart – System neustarten oder wieder starten
Der reboot Befehl startet das Linux-Betriebssystem neu, meldet alle Benutzer ab und startet das System sicher neu. Er synchronisiert die Festplatten und fährt das System sauber herunter, bevor es neu gestartet wird.
Beispielsweise:
rebootSystem neu starten.
Dies startet das Betriebssystem sofort neu. reboot ist eine einfache Alternative zu shutdown -r.
82. systemctl – Steuern Sie den systemd System- und Dienstmanager
Der Befehl systemctl ermöglicht es Ihnen, systemd-Dienste wie das Starten, Stoppen, Neustarten oder Neuladen zu verwalten. Systemd ist das neue Init-System, das in den meisten modernen Linux-Distributionen verwendet wird und SysV init ersetzt.
Zum Beispiel:
systemctl start apache2==== AUTORISIERUNG FÜR org.freedesktop.systemd1.manage-units ===Authentifizierung ist erforderlich, um 'apache2.service' zu starten.Authentifizierung als: BenutzernamePasswort:==== AUTORISIERUNG ABGESCHLOSSEN ===
Dies startet den Apache2-Dienst nach der Authentifizierung.
83. Dienst – Ein System V Init-Skript ausführen
Der service Befehl führt System V init-Skripte zur Steuerung von Diensten aus. Dies ermöglicht das Starten, Stoppen, Neustarten und Neuladen von Diensten, die unter dem traditionellen SysV init verwaltet werden.
Zum Beispiel:
service iptables start[ ok ] Starten von iptables (über systemctl): iptables.service.
Der obige Befehl startet den iptables Firewall-Dienst mit seinem SysV-Init-Skript.
Andere Linux-Befehle zum Ausprobieren
-
mount– Laufwerke ins System einbinden oder „anfügen“. -
umount– Laufwerke vom System „entfernen“. -
xargs– Erstellt und führt Befehle aus, die über die Standardeingabe bereitgestellt werden. -
alias– Erstellen von Abkürzungen für lange oder komplexe Befehle. -
jobs– Listet Programme auf, die derzeit im Hintergrund laufen. -
bg– Setzt einen gestoppten oder pausierten Hintergrundprozess fort. -
killall– Beendet Prozesse nach Programmnamen statt nach PID. -
history– Zeigt zuvor verwendete Befehle innerhalb der aktuellen Terminal-Sitzung an. -
man– Zugriff auf Hilfsanleitungen für Befehle direkt im Terminal. -
screen– Verwaltet mehrere Terminal-Sitzungen aus einem einzigen Fenster. -
ssh– Stellt sichere verschlüsselte Verbindungen zu entfernten Servern her. -
tcpdump– Erfasst Netzwerkverkehr basierend auf spezifischen Kriterien. -
watch– Wiederholt einen Befehl in Intervallen und hebt Unterschiede in der Ausgabe hervor. -
tmux– Terminal-Multiplexer für persistente Sitzungen und Aufteilung. -
nc– Öffnet TCP- oder UDP-Verbindungen für Tests und Datentransfer. -
nmap– Host-Erkennung, Port-Scanning und Betriebssystem-Fingerprinting. -
strace– Debugging von Prozessen durch Nachverfolgung von Betriebssystemsignalen und -aufrufen.
7 wichtige Tipps für die Verwendung von Linux-Befehlen
- Kenne deine Shell: Bash, zsh, fish? Verschiedene Shells haben einzigartige Funktionen. Wähle diejenige, die am besten zu deinen Bedürfnissen passt.
- Beherrsche die Kern-Utils:
ls,cat,grep,sed,awk, etc bilden das Herzstück eines Linux-Toolkits. - Halte dich an Pipelines: Vermeide übermäßigen Gebrauch von temporären Dateien. Verbinde Programme clever miteinander.
- Prüfe vor dem Überschreiben: Überprüfe immer doppelt, bevor du Dateien mit
>und>>überschreibst. - Verfolge deine Workflows: Dokumentiere komplexe Befehle und Workflows, um sie später erneut zu verwenden oder zu teilen.
- Erstelle deine eigenen Tools: Schreibe einfache Shell-Skripte und Aliase für häufige Aufgaben.
- Beginne ohne
sudo: Benutze anfangs ein Standardbenutzerkonto, um Berechtigungen zu verstehen.
Und denken Sie daran, neue Befehle auf virtuellen Maschinen oder VPS-Servern zu testen, damit sie Ihnen in Fleisch und Blut übergehen, bevor Sie sie auf Produktionsservern verwenden.
VPS Hosting
Ein Virtual Private Server (VPS) ist eine virtuelle Plattform, die Daten speichert. Viele Webhosts bieten VPS-Hosting-Pläne an, die Website-Betreibern einen dedizierten, privaten Bereich auf einem gemeinsam genutzten Server bieten.
Mehr lesenBesseres Linux-Hosting mit DreamHost
Nachdem Sie die wesentlichen Linux-Befehle beherrschen, benötigen Sie auch einen Hosting- und Serveranbieter, der Ihnen volle Kontrolle gibt, um die Kraft und Flexibilität von Linux voll auszuschöpfen.
Hier glänzt DreamHost.
DreamHosts optimierte Linux-Infrastruktur ist perfekt, um Ihre Apps, Websites und Dienste zu betreiben:
- Schnelles Webhosting auf modernen Linux-Servern.
- SSH-Shell-Zugang für die Steuerung über die Befehlszeile.
- Anpassbare PHP-Versionen einschließlich PHP 8.0.
- Apache oder NGINX Webserver.
- Verwaltete MySQL, PostgreSQL, Redis Datenbanken.
- 1-Klick-Installationen von Apps wie WordPress und Drupal.
- SSD-beschleunigter NVMe-Speicher für Geschwindigkeit.
- Kostenfreie automatische Erneuerung von Let’s Encrypt SSL-Zertifikaten.
Die Experten von DreamHost können Ihnen helfen, das Beste aus der Linux-Plattform herauszuholen. Unsere Server sind sorgfältig für Sicherheit, Leistung und Zuverlässigkeit konfiguriert.
Starten Sie Ihr nächstes Projekt auf einer Linux-Hosting-Plattform, der Sie vertrauen können. Fangen Sie an mit robustem, skalierbarem Hosting auf DreamHost.com.

