
Umgebungsvariablen ermöglichen die Konfiguration von Anwendungen ohne Codeänderung. Sie trennen externe Daten von der Anwendungslogik, was für aufstrebende Entwickler (und auch einige erfahrene) ziemlich rätselhaft bleiben kann.
Durch diesen praktischen Leitfaden werden wir den Schleier um Umgebungsvariablen lüften, damit Sie verstehen können, was sie beinhalten, warum sie wichtig sind und wie Sie Umgebungsvariablen selbstbewusst nutzen können.
Holen Sie sich Ihr Lieblingsgetränk (und vielleicht einige Kekse), denn wir werden uns damit befassen. Lassen Sie uns die Konzepte von Umgebungsvariablen von Grund auf neu entpacken.
Was sind Umgebungsvariablen?

Umgebungsvariablen sind dynamische benannte Werte, die das Verhalten von laufenden Prozessen auf einem Computer beeinflussen können. Einige Schlüsseleigenschaften von Umgebungsvariablen sind:
- Benannt: Haben beschreibende Variablennamen wie APP_MODE und DB_URL.
- Extern: Werte werden außerhalb des App-Codes über Dateien, Befehlszeilen und Systeme festgelegt.
- Dynamisch: Kann Variablen aktualisieren, ohne Apps neu zu starten.
- Konfiguriert: Code basiert auf Variablen, definiert diese jedoch nicht.
- Entkoppelt: Keine Notwendigkeit, Codekonfigurationen zu ändern, sobald Variablen festgelegt sind.
Hier ist eine Analogie. Stellen Sie sich vor, Sie folgen einem Rezept für Schokoladenkekse. Das Rezept könnte lauten:
- 1 Tasse Zucker hinzufügen
- 1 Stück weiche Butter hinzufügen
- 2 Eier hinzufügen
Anstelle dieser fest codierten Werte könnten Sie stattdessen Umgebungsvariablen verwenden:
- Füge $SUGAR Tasse Zucker hinzu
- Füge $BUTTER Stücke weiche Butter hinzu
- Füge $EGGS Eier hinzu
Bevor Sie die Cookies machen, würden Sie diese Umgebungsvariablennamen auf Werte Ihrer Wahl setzen:
SUGAR=1
BUTTER=1
EGGS=2Also, wenn Sie dem Rezept folgen, würden Ihre Zutaten sich wie folgt zusammenstellen:
- 1 Tasse Zucker hinzufügen
- 1 Stück weiche Butter hinzufügen
- 2 Eier hinzufügen
Dies ermöglicht Ihnen, das Cookie-Rezept zu konfigurieren, ohne den Rezeptcode zu ändern.
Das gleiche Konzept gilt für Berechnung und Entwicklung. Umgebungsvariablen ermöglichen es Ihnen, die Umgebung zu ändern, in der ein Prozess ausgeführt wird, ohne den zugrunde liegenden Code zu ändern. Hier sind einige häufige Beispiele:
- Die Umgebung auf „development“ oder „production“ einstellen
- API-Schlüssel für externe Dienste konfigurieren
- Geheime Schlüssel oder Anmeldeinformationen übergeben
- Bestimmte Funktionen ein- und ausschalten
Umgebungsvariablen bieten große Flexibilität. Sie können denselben Code in mehrere Umgebungen bereitstellen, ohne den Code selbst zu ändern. Aber lassen Sie uns weiter verstehen, warum sie wertvoll sind.
Warum sind Umgebungsvariablen wertvoll?

Betrachten Sie Umgebungsvariablen wie Anwendungsknöpfe, die verwendet werden, um Einstellungen vorzunehmen. Wir werden in Kürze ausgezeichnete Anwendungsfälle erkunden.
Lassen Sie uns die Intuition verstärken, warum Umgebungsvariablen wichtig sind!
Grund #1: Sie trennen Anwendungscode von Konfigurationen

Das direkte Einprogrammieren von Konfigurationen und Zugangsdaten in Ihren Code kann zu allerlei Problemen führen:
- Zufällige Commits in die Versionskontrolle
- Neuaufbau und Neubereitstellung von Code nur um einen Wert zu ändern
- Konfigurationsprobleme beim Übertragen zwischen Umgebungen
Das führt auch zu unordentlichem Code:
import os
# Fest vorgegebene Konfiguration
DB_USER = 'appuser'
DB_PASS = 'password123'
DB_HOST = 'localhost'
DB_NAME = 'myappdb'
def connect_to_db():
print(f"Verbindung zu {DB_USER}:{DB_PASS}@{DB_HOST}/{DB_NAME}")
connect_to_db()Dies verknüpft Geschäftslogik mit Konfigurationsdetails. Enge Kopplung macht die Wartung im Laufe der Zeit mühsam:
- Änderungen erfordern das Modifizieren des Quellcodes
- Risiko des Veröffentlichens von Geheimnissen in der Quellcodeverwaltung
Die Verwendung von Umgebungsvariablen reduziert diese Probleme. Zum Beispiel können Sie die Umgebungsvariablen DB_USER und DB_NAME festlegen.
# .env Datei
DB_USER=appuser
DB_PASS=password123
DB_HOST=localhost
DB_NAME=myappdbDer Anwendungscode kann bei Bedarf auf die Umgebungsvariablen zugreifen, wodurch der Code sauber und einfach bleibt.
import os
# Konfiguration aus Umgebung laden
DB_USER = os.environ['DB_USER']
DB_PASS = os.environ['DB_PASS']
DB_HOST = os.environ['DB_HOST']
DB_NAME = os.environ['DB_NAME']
def connect_to_db():
print(f"Verbindung zu {DB_USER}:{DB_PASS}@{DB_HOST}/{DB_NAME}")
connect_to_db()Umgebungsvariablen trennen die Konfiguration sauber vom Code, indem sie sensible Werte in die Umgebung abstrahieren.
Sie können denselben Code von der Entwicklung in die Produktion übertragen, ohne etwas zu ändern. Die Umgebungsvariablen können sich zwischen den Umgebungen unterscheiden, ohne den Code zu beeinflussen.
Grund #2: Sie vereinfachen die Konfiguration von Anwendungen
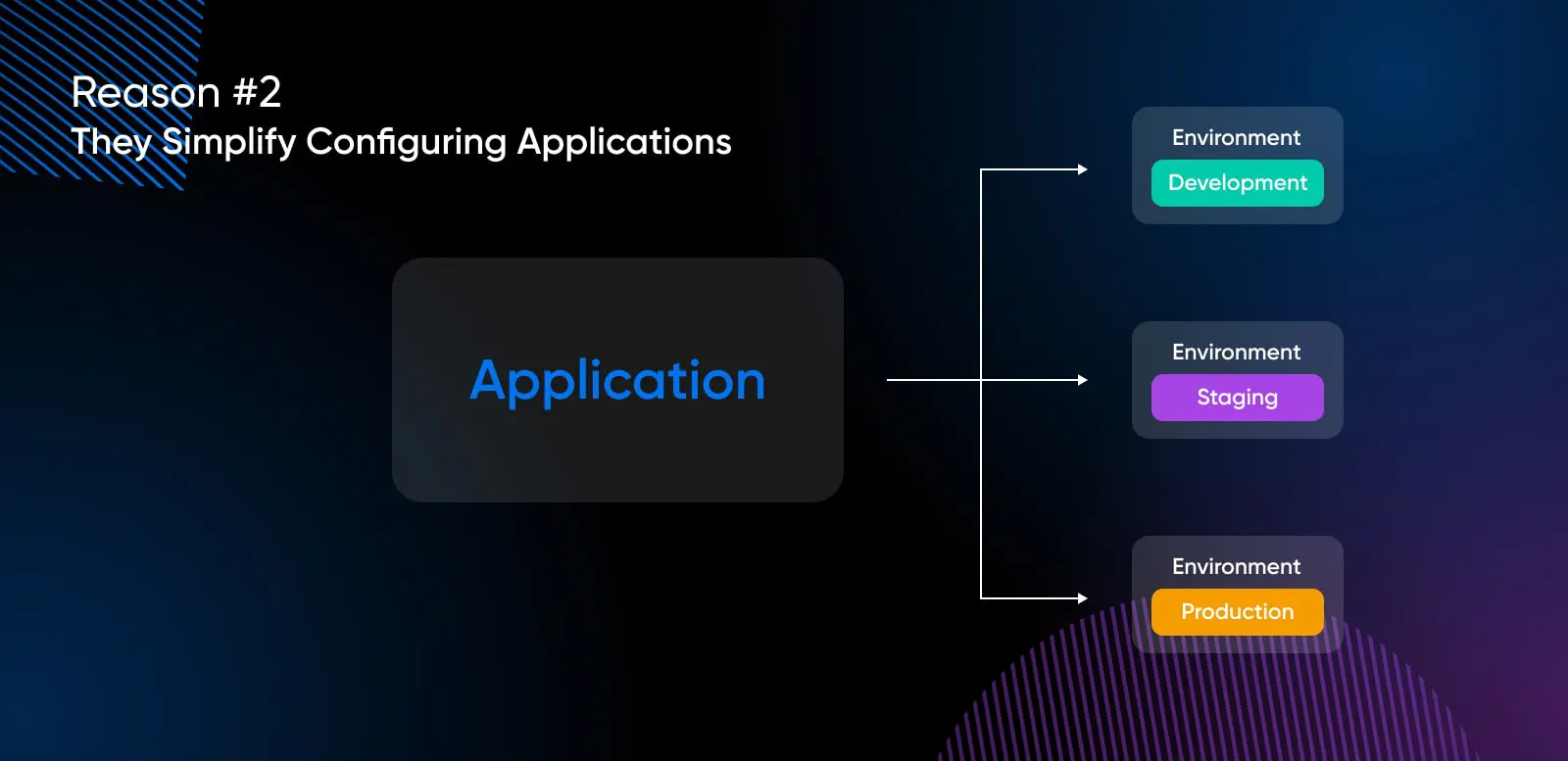
Umgebungsvariablen vereinfachen die Anpassung von Konfigurationen, ohne den Code zu berühren:
# .env file:
DEBUG=trueHier ist, wie wir es innerhalb der Skriptdatei verwenden könnten:
# Scriptinhalt:
import os
DEBUG = os.environ.get('DEBUG') == 'true'
if DEBUG:
print("Im DEBUG-Modus")Das Umschalten des Debug-Modus erfordert nur ein Update der .env-Datei – es sind keine Codeänderungen, Neubauten oder Neuveröffentlichungen erforderlich. „Env vars“ kurz gesagt, helfen auch, nahtlos über Umgebungen hinweg zu deployen:
import os
# Abrufen der Umgebungsvariablen zur Bestimmung der aktuellen Umgebung (Produktion oder Staging)
current_env = os.getenv('APP_ENV', 'Staging') # Standardmäßig auf 'Staging' gesetzt, falls nicht festgelegt
# Produktions-API-Schlüssel
PROD_API_KEY = os.environ['PROD_API_KEY']
# Staging-API-Schlüssel
STG_API_KEY = os.environ['STG_API_KEY']
# Logik, die api_key basierend auf der aktuellen Umgebung festlegt
if current_env == 'production':
api_key = PROD_API_KEY
else:
api_key = STG_API_KEY
# Initialisierung des API-Clients mit dem entsprechenden API-Schlüssel
api = ApiClient(api_key)Derselbe Code kann separate API-Schlüssel für Produktion vs Staging ohne Änderungen verwenden.
Und zuletzt ermöglichen sie Funktionswechsel ohne neue Bereitstellungen:
NEW_FEATURE = os.environ['NEW_FEATURE'] == 'true'
if NEW_FEATURE:
enableNewFeature()Das Ändern der NEW_FEATURE Variable aktiviert sofort Funktionen in unserem Code. Die Schnittstelle zum Aktualisieren von Konfigurationen hängt von den Systemen ab:
- Cloud-Plattformen wie Heroku verwenden Web-Armaturenbretter
- Server verwenden OS-Befehlswerkzeuge
- Lokale Entwicklung kann .env-Dateien verwenden
Umgebungsvariablen sind vorteilhaft beim Erstellen von Anwendungen, da sie es Benutzern ermöglichen, Elemente nach ihren Anforderungen zu konfigurieren.
Grund #3: Sie verwalten Geheimnisse und Anmeldedaten

Das Überprüfen von Geheimnissen wie API-Schlüsseln, Passwörtern und privaten Schlüsseln direkt im Quellcode birgt erhebliche Sicherheitsrisiken:
# Vermeiden Sie das Offenlegen von Geheimnissen im Code!
STRIPE_KEY = 'sk_live_1234abc'
DB_PASSWORD = 'password123'
stripe.api_key = STRIPE_KEY
db.connect(DB_PASSWORD)Diese Anmeldeinformationen sind jetzt offen gelegt, wenn dieser Code in ein öffentliches GitHub-Repository eingefügt wird!
Umgebungsvariablen verhindern das Austreten von Geheimnissen, indem sie diese externalisieren:
import os
STRIPE_KEY = os.environ.get('STRIPE_KEY')
DB_PASS = os.environ.get('DB_PASS')
stripe.api_key = STRIPE_KEY
db.connect(DB_PASS)Die tatsächlichen Geheimwerte werden in einer lokalen .env Datei festgelegt.
# .env Datei
STRIPE_KEY=sk_live_1234abc
DB_PASS=password123Vergessen Sie nicht, die .env-Datei in .gitignore aufzunehmen, um Geheimnisse aus der Quellenkontrolle herauszuhalten. Dies beinhaltet die Definition der .env-Datei in einer .gitignore-Datei im Wurzelverzeichnis eines Repos, die git anweist, die Datei beim Erstellen eines Commits zu ignorieren.
Dies trennt geheime Definitionen vom Anwendungscode und lädt sie während der Laufzeit sicher aus geschützten Umgebungen. Das Risiko, Anmeldeinformationen versehentlich preiszugeben, verringert sich erheblich.
Grund #4: Sie fördern die Konsistenz
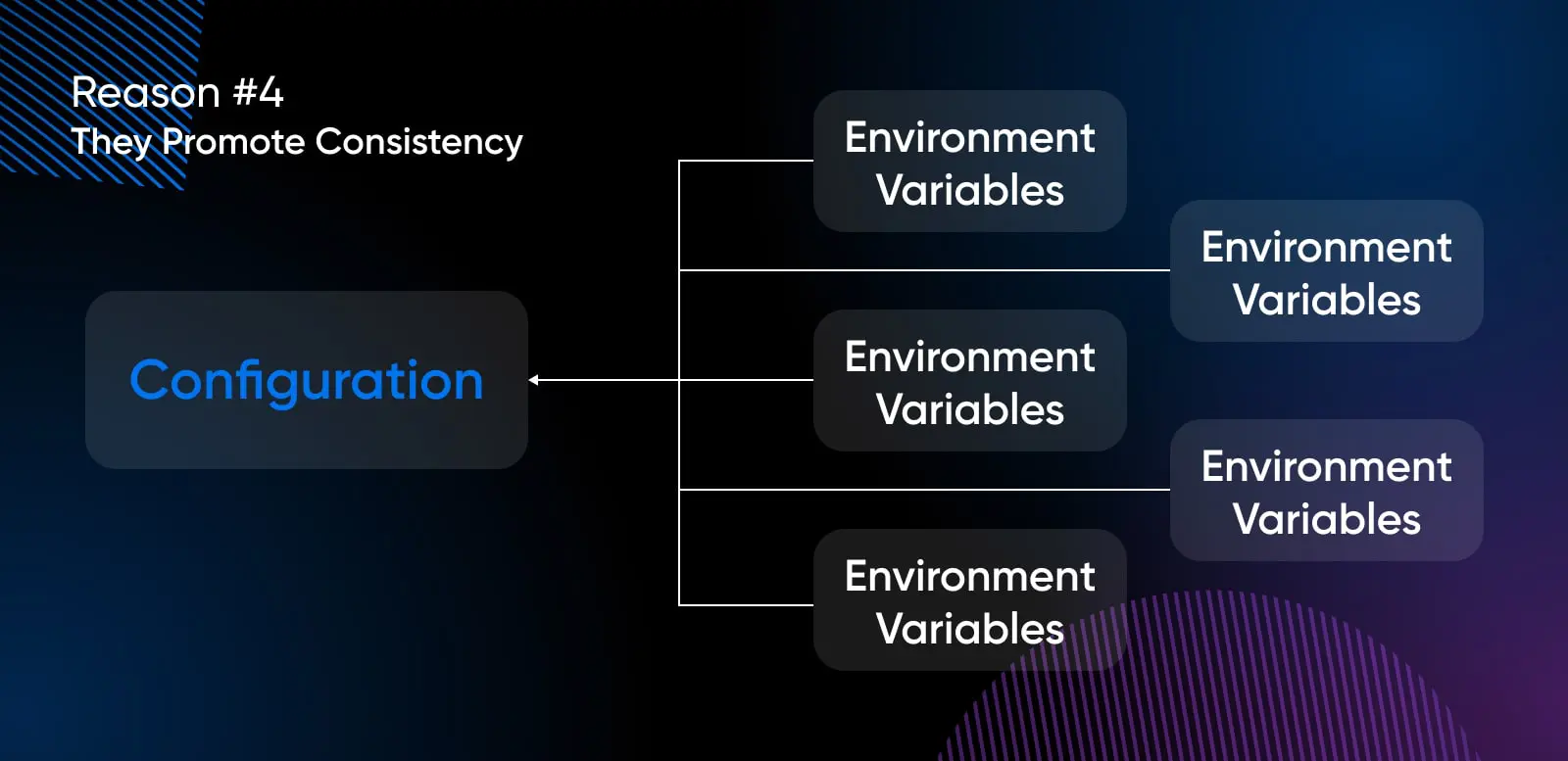
Stellen Sie sich vor, Sie hätten unterschiedliche Konfigurationsdateien für Entwicklungs-, QA- und Produktionsumgebungen:
# Entwicklung
DB_HOST = 'localhost'
DB_NAME = 'appdb_dev'
# Produktion
DB_HOST = 'db.myapp.com'
DB_NAME = 'appdb_prod'Diese Diskrepanz führt zu subtilen Fehlern, die schwer zu erkennen sind. Code, der in der Entwicklung einwandfrei funktioniert, könnte plötzlich in der Produktion aufgrund von nicht übereinstimmenden Konfigurationen ausfallen.
Umgebungsvariablen lösen dies, indem sie die Konfiguration an einem Ort zentralisieren:
DB_HOST=db.myapp.com
DB_NAME=appdb_prodNun werden dieselben Variablen konsistent über alle Umgebungen hinweg verwendet. Sie müssen sich keine Sorgen mehr über zufällige oder falsche Einstellungen machen, die in Kraft treten.
Der Anwendungscode bezieht sich einfach auf die Variablen:
import os
db_host = os.environ['DB_HOST']
db_name = os.environ['DB_NAME']
db.connect(db_host, db_name)Unabhängig davon, ob die App lokal oder auf einem Produktionsserver läuft, verwendet sie immer den richtigen Datenbankhost und -namen.
Diese Einheitlichkeit reduziert Fehler, verbessert die Vorhersagbarkeit und macht die App insgesamt robuster. Entwickler können darauf vertrauen, dass der Code sich in jeder Umgebung identisch verhält.
Wie können Sie Umgebungsvariablen definieren
Umgebungsvariablen können an mehreren Stellen definiert werden, was Flexibilität bei der Einstellung und dem Zugriff auf sie über Prozesse und Systeme hinweg ermöglicht.
1. Betriebssystem-Umgebungsvariablen
Die meisten Betriebssysteme bieten integrierte Mechanismen zur Definition globaler Variablen. Dies macht die Variablen systemweit für alle Benutzer, Anwendungen usw. zugänglich.
Auf Linux/Unix-Systemen können Variablen in Shell-Startskripten definiert werden.
Zum Beispiel kann ~/.bashrc verwendet werden, um benutzerspezifische Variablen festzulegen, während /etc/environment für systemweite Variablen verwendet wird, auf die alle Benutzer zugreifen können.
Variablen können auch inline gesetzt werden, bevor Befehle mit dem Export-Befehl ausgeführt oder direkt durch den env-Befehl in bash eingestellt werden:
# In ~/.bashrc
export DB_URL=localhost
export APP_PORT=3000# In /etc/environment
DB_HOST=localhost
DB_NAME=mydatabaseVariablen können auch inline gesetzt werden, bevor Befehle ausgeführt werden:
export TOKEN=abcdef
python app.pyVariablen auf Betriebssystemebene zu definieren macht sie global verfügbar, was sehr hilfreich ist, wenn Sie die App ausführen möchten, ohne von internen Werten abhängig zu sein.
Sie können auch definierte Variablen in Skripten oder Befehlszeilenargumenten referenzieren.
python app.py --db-name $DB_NAME --db-host $DB_HOST --batch-size $BATCH_SIZE2. Definieren von Umgebungsvariablen im Anwendungscode
Zusätzlich zu Betriebssystem-Ebene Variablen können Umgebungsvariablen direkt im Anwendungscode definiert und während des Betriebs abgerufen werden.
Das os.environ-Wörterbuch in Python enthält alle derzeit definierten Umgebungsvariablen. Wir können neue hinzufügen, indem wir einfach Schlüssel-Wert-Paare hinzufügen:
Umgebungsvariablen können auch direkt im Anwendungscode definiert und abgerufen werden. In Python enthält das os.environ Wörterbuch alle definierten Umgebungsvariablen:
import os
os.environ["API_KEY"] = "123456"
api_key = os.environ.get("API_KEY")Das os.environ Wörterbuch erlaubt das dynamische Setzen und Abrufen von Umgebungsvariablen innerhalb von Python-Code.
Die meisten Sprachen werden mit ihren Bibliotheken gebündelt, die Zugriff auf Umgebungsvariablen während der Laufzeit bieten.
Sie können auch Frameworks wie Express, Django und Laravel verwenden, um tiefere Integrationen zu ermöglichen, wie das automatische Laden von .env-Dateien, die Umgebungsvariablen enthalten.
3. Erstellen lokaler Konfigurationsdateien für Umgebungsvariablen
Zusätzlich zu systemebenen Variablen können Umgebungsvariablen aus lokalen Konfigurationsdateien einer Anwendung geladen werden. Dies hält Konfigurationsdetails getrennt vom Code, auch für lokale Entwicklung und Tests.
Einige beliebte Ansätze:
.env Files
Das .env Dateiformat, das durch Node.js populär wurde, bietet eine praktische Möglichkeit, Umgebungsvariablen im Schlüssel-Wert-Format anzugeben:
# .env
DB_URL=localhost
API_KEY=123456Web-Frameworks wie Django und Laravel laden automatisch Variablen, die in .env-Dateien definiert sind, in die Anwendungsumgebung. Für andere Sprachen wie Python behandeln Bibliotheken wie python-dotenv das Importieren von .env-Dateien:
from dotenv import load_dotenv
load_dotenv() # Lädt .env Variablen
print(os.environ['DB_URL']) # localhostDer Vorteil der Verwendung von .env-Dateien besteht darin, dass sie die Konfiguration sauber und getrennt halten, ohne Änderungen am Code vorzunehmen.
JSON-Konfigurationsdateien
Für komplexere Konfigurationsanforderungen, die mehrere Umgebungsvariablen umfassen, hilft die Verwendung von JSON- oder YAML-Dateien, die Variablen zu organisieren:
// config.json
{
"api_url": "https://api.example.com",
"api_key": "123456",
"port": 3000
}Der Anwendungscode kann dann diese JSON-Daten schnell als Wörterbuch laden, um auf konfigurierte Variablen zuzugreifen:
import json
config = json.load('config.json')
api_url = config['api_url']
api_key = config['api_key']
port = config['port'] # 3000Dies verhindert unordentliche dotenv-Dateien bei der Verwaltung mehrerer App-Konfigurationen.
Wie greifen Sie auf Umgebungsvariablen in verschiedenen Programmiersprachen zu?
Unabhängig davon, wie wir Umgebungsvariablen definieren, benötigen unsere Anwendungen eine konsistente Methode, um Werte zur Laufzeit zu suchen.
Obwohl verschiedene Methoden existieren, Umgebungsvariablen zu definieren, benötigt der Anwendungscode einen standardisierten Weg, um sie zur Laufzeit unabhängig von der Sprache zugreifen zu können. Hier ist eine Übersicht über Techniken, um auf Umgebungsvariablen in beliebten Sprachen zuzugreifen:
Python
Python stellt das os.environ Wörterbuch bereit, um definierte Umgebungsvariablen zu zugreifen:
import os
db = os.environ.get('DB_NAME')
print(db)Wir können eine Variable mit os.environ.get() abrufen, das None zurückgibt, wenn sie nicht definiert ist. Oder direkt über os.environ() zugreifen, was einen KeyError auslöst, wenn sie nicht vorhanden ist.
Zusätzliche Methoden wie os.getenv() und os.environ.get() ermöglichen es, Standardwerte festzulegen, falls nicht gesetzt.
JavaScript (Node.js)
In Node.js JavaScript-Code sind Umgebungsvariablen auf dem globalen process.env-Objekt verfügbar:
// Get env var
const db = process.env.DB_NAME;
console.log(db);Wenn undefiniert, wird process.env undefiniert enthalten. Wir können auch Standardwerte bereitstellen wie:
const db = process.env.DB_NAME || 'defaultdb';Ruby
Ruby-Anwendungen greifen über den ENV-Hash auf Umgebungsvariablen zu:
# Zugriffsvariable
db = ENV['DB_NAME']
puts dbWir können auch einen Standardwert übergeben, wenn der gewünschte Schlüssel nicht existiert:
db = ENV.fetch('DB_NAME', 'defaultdb')PHP
PHP stellt globale Methoden getenv(), $_ENV und $_SERVER zur Verfügung, um auf Umgebungsvariablen zuzugreifen:
// Umgebungsvariable abrufen
$db_name = getenv('DB_NAME');
// Oder auf $_ENV oder $_SERVER Arrays zugreifen
$db_name = $_ENV['DB_NAME'];Je nach der Variablenquelle können sie in verschiedenen Globals verfügbar sein.
Java
In Java gibt die Methode System.getenv() Umgebungsvariablen zurück, auf die zugegriffen werden kann:
String dbName = System.getenv("DB_NAME");Dies ermöglicht den Zugriff auf global auf Systemebene in Java definierte Variablen.
Vorläufig einige bewährte Methoden zur Hygiene von Umgebungsvariablen.
Sicherheitsleitfaden für Umgebungsvariablen

Wenn es darum geht, Umgebungsvariablen sicher zu verwalten, sollten wir mehrere bewährte Verfahren beachten.
Speichern Sie niemals sensible Informationen im Code
Zuallererst sollten niemals sensible Informationen wie Passwörter, API-Schlüssel oder Tokens direkt im Code gespeichert werden.
Es mag verlockend sein, einfach ein Datenbankpasswort oder einen Verschlüsselungsschlüssel in Ihren Quellcode für den schnellen Zugriff hart zu kodieren, aber widerstehen Sie diesem Drang!
Wenn Sie versehentlich diesen Code in ein öffentliches Repository auf GitHub übertragen, senden Sie im Grunde Ihre Geheimnisse an die ganze Welt. Stellen Sie sich vor, ein Hacker erlangt Zugriff auf Ihre Produktionsdatenbank-Zugangsdaten, nur weil sie im Klartext in Ihrer Codebasis liegen. Beängstigender Gedanke, nicht wahr?
Verwenden Sie stattdessen immer Umgebungsvariablen, um jegliche Art von sensibler Konfiguration zu speichern. Bewahren Sie Ihre Geheimnisse an einem sicheren Ort wie einer .env-Datei oder einem Tool zur Verwaltung von Geheimnissen auf und referenzieren Sie sie in Ihrem Code über Umgebungsvariablen. Zum Beispiel, anstatt so etwas in Ihrem Python-Code zu tun:
db_password = "supers3cr3tpassw0rd"Sie würden dieses Passwort in einer Umgebungsvariablen wie folgt speichern:
# .env file
DB_PASSWORD=supers3cr3tpassw0rdUnd dann greifen Sie in Ihrem Code darauf zu wie folgt:
import os
db_password = os.environ.get('DB_PASSWORD')Auf diese Weise bleiben Ihre Geheimnisse sicher, auch wenn Ihr Quellcode kompromittiert wird. Umgebungsvariablen dienen als sichere Abstraktionsschicht.
Umweltspezifische Variablen verwenden
Ein weiteres Verfahren ist die Verwendung unterschiedlicher Umgebungsvariablen für jede Anwendungsumgebung, wie Entwicklung, Staging und Produktion.
Sie möchten nicht versehentlich eine Verbindung zu Ihrer Produktionsdatenbank herstellen, während Sie lokal entwickeln, nur weil Sie vergessen haben, eine Konfigurationsvariable zu aktualisieren! Setzen Sie Namensräume für Ihre Umgebungsvariablen für jede Umgebung:
# Dev
DEV_API_KEY=abc123
DEV_DB_URL=localhost
# Production
PROD_API_KEY=xyz789
PROD_DB_URL=proddb.amazonaws.comDann beziehen Sie sich auf die entsprechenden Variablen in Ihrem Code, abhängig von der aktuellen Umgebung. Viele Frameworks wie Rails bieten für diesen Zweck umgebungsspezifische Konfigurationsdateien an.
Halten Sie Geheimnisse außerhalb der Versionskontrolle
Es ist auch entscheidend, Ihre .env- und Konfigurationsdateien, die Geheimnisse enthalten, außerhalb der Versionskontrolle zu halten. Fügen Sie .env zu Ihrer .gitignore hinzu, damit Sie es nicht versehentlich in Ihr Repository einchecken.
Sie können git-secrets verwenden, um vor jedem Commit nach sensiblen Informationen zu scannen. Für zusätzliche Sicherheit verschlüsseln Sie Ihre Geheimnisse-Datei, bevor Sie sie speichern. Werkzeuge wie Ansible Vault und BlackBox können dabei helfen.
Sichere Geheimnisse auf Produktionsservern
Beim Verwalten von Umgebungsvariablen auf Ihren Produktionsservern sollten Sie vermeiden, diese über Kommandozeilenargumente zu setzen, die über die Prozesstabelle inspiziert werden können.
Verwenden Sie stattdessen die Umgebungsverwaltungstools Ihres Betriebssystems oder Ihrer Container-Orchestrierungsplattform. Zum Beispiel können Sie Kubernetes Secrets verwenden, um Geheimnisse sicher zu speichern und Ihren Anwendungs-Pods zugänglich zu machen.
Verwenden Sie starke Verschlüsselungsalgorithmen
Verwenden Sie robuste und moderne Verschlüsselungsalgorithmen beim Verschlüsseln Ihrer Geheimnisse, ob in Übertragung oder im Ruhezustand. Vermeiden Sie veraltete Algorithmen wie DES oder MD5, die bekannte Schwachstellen haben. Wählen Sie stattdessen branchenübliche Algorithmen wie AES-256 für symmetrische Verschlüsselung und RSA-2048 oder ECDSA für asymmetrische Verschlüsselung.
Regelmäßig Geheimnisse rotieren
Drehen Sie Ihre Geheimnisse regelmäßig, besonders wenn Sie vermuten, dass sie kompromittiert worden sein könnten. Behandeln Sie Geheimnisse, wie Sie ein Passwort behandeln würden — aktualisieren Sie sie alle paar Monate. Ein Geheimnisverwaltungstool wie Hashicorp Vault oder AWS Secrets Manager kann dabei helfen, diesen Prozess zu automatisieren.
Seien Sie vorsichtig mit Protokollierung und Fehlerberichterstattung
Seien Sie vorsichtig mit Protokollierung und Fehlerberichterstattung. Stellen Sie sicher, dass Sie keine Umgebungsvariablen protokollieren, die sensible Werte enthalten. Wenn Sie ein Fehlerverfolgungstool von Drittanbietern verwenden, konfigurieren Sie es so, dass es sensible Daten bereinigt. Das Letzte, was Sie wollen, ist, dass Ihre Geheimnisse in einem Stack-Trace auf einem Dashboard für Ausnahmeberichte erscheinen!
Wann sollte man Umgebungsvariablen vermeiden?
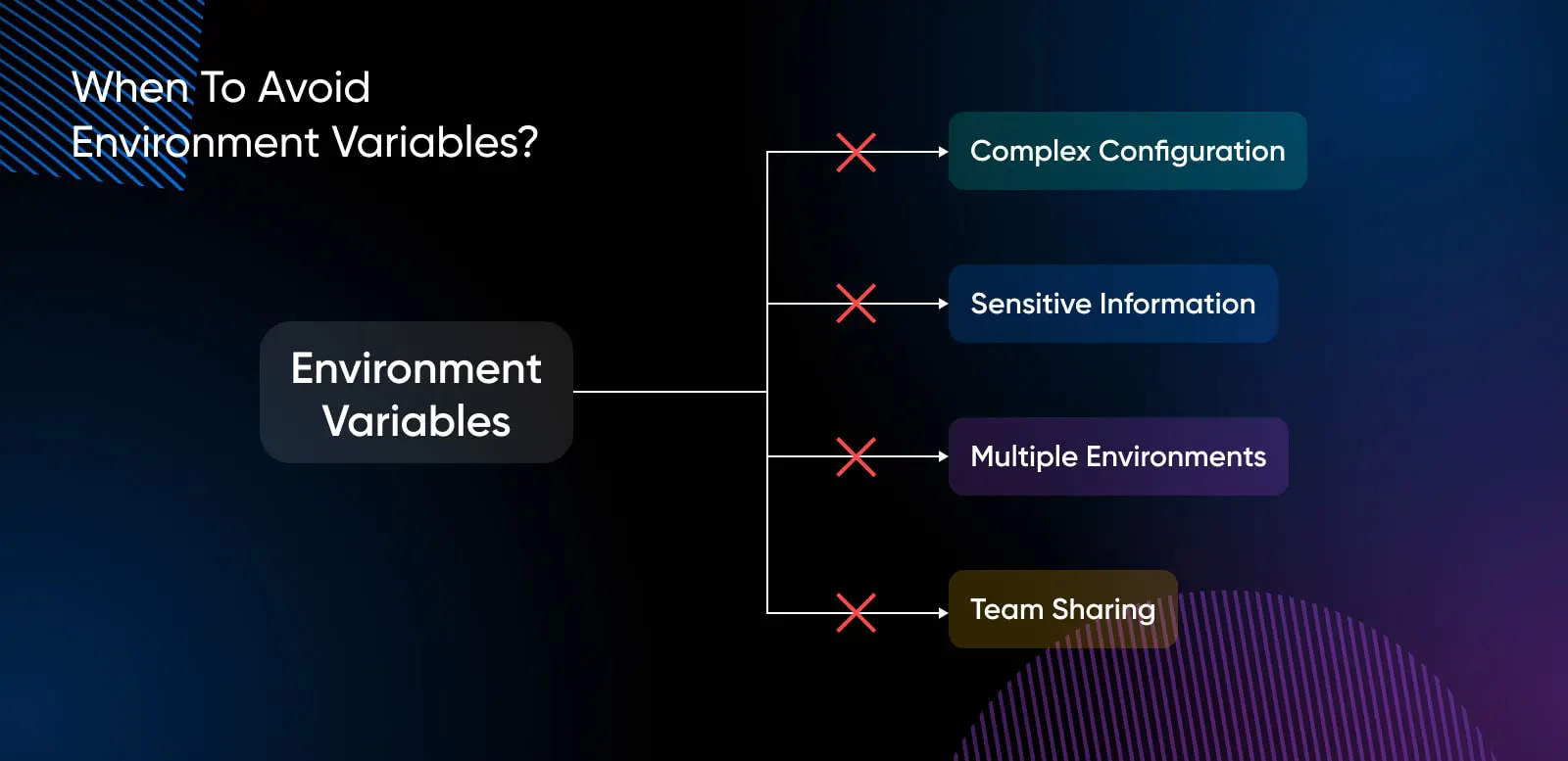
Es gibt mehrere Fälle, in denen Umgebungsvariablen vermieden werden sollten:
Verwaltung komplexer Konfigurationen
Die Verwendung von Umgebungsvariablen zur Verwaltung der Konfiguration für komplexe Softwaresysteme kann unübersichtlich und fehleranfällig werden. Mit der zunehmenden Anzahl an Konfigurationsparametern endet man mit langen Namen für Umgebungsvariablen, die unbeabsichtigt kollidieren können. Es gibt auch keine einfache Möglichkeit, zusammengehörige Konfigurationswerte zu organisieren.
Anstelle von Umgebungsvariablen sollten Sie die Verwendung von Konfigurationsdateien in einem Format wie JSON oder YAML in Betracht ziehen. Diese ermöglichen es Ihnen:
- Gruppieren Sie verwandte Konfigurationsparameter zusammen in einer verschachtelten Struktur.
- Vermeiden Sie Namenskonflikte, indem Sie Konfigurationen in Bereiche und Namensräume kapseln.
- Definieren Sie benutzerdefinierte Datentypen anstelle von nur Zeichenketten.
- Konfigurationen schnell mit einem Texteditor ansehen und ändern.
Speicherung sensibler Informationen
Obwohl Umgebungsvariablen das Einspeisen externer Konfigurationen wie API-Schlüssel, Datenbankpasswörter usw. erleichtern, kann dies Sicherheitsprobleme verursachen.
Das Problem ist, dass Umgebungsvariablen global in einem Prozess zugänglich sind. Wenn also ein Exploit in einem Teil Ihrer Anwendung existiert, könnte dies Geheimnisse gefährden, die in Umgebungsvariablen gespeichert sind.
Ein sichererer Ansatz ist die Verwendung eines Geheimdienstverwaltungsdienstes, der Verschlüsselung und Zugriffskontrolle handhabt. Diese Dienste ermöglichen das Speichern sensibler Daten extern und bieten SDKs zum Abrufen von Anwendungswerten.
Denken Sie also daran, eine dedizierte Lösung zur Verwaltung von Geheimnissen anstelle von Umgebungsvariablen für Anmeldeinformationen und private Schlüssel zu verwenden. Dies verringert das Risiko, sensible Daten durch Exploits oder unbeabsichtigtes Protokollieren versehentlich offenzulegen.
Arbeiten mit mehreren Umgebungen
Das Verwalten von Umgebungsvariablen kann mühsam werden, wenn Anwendungen wachsen und in verschiedenen Umgebungen (dev, staging, staging, prod) eingesetzt werden. Es kann vorkommen, dass Konfigurationsdaten auf verschiedene Bash-Skripte, Deployment-Tools usw. verteilt sind.
Eine Konfigurationsverwaltungslösung hilft dabei, alle umgebungsspezifischen Einstellungen an einem zentralen Ort zu konsolidieren. Dies könnte Dateien in einem Repository, ein dedizierter Konfigurationsserver oder integriert mit Ihren CI/CD-Pipelines sein.
Wenn das Ziel darin besteht, Umgebungsvariablen nicht zu duplizieren, macht eine einzige Quelle der Wahrheit für Konfigurationen mehr Sinn.
Konfigurationen über Teams teilen
Da Umgebungsvariablen lokal pro Prozess geladen werden, wird das Teilen und Synchronisieren von Konfigurationsdaten über verschiedene Teams hinweg, die an derselben Anwendung oder Dienstleistungssuite arbeiten, sehr schwierig.
Jedes Team kann seine Kopie von Konfigurationswerten in verschiedenen Bash-Skripten, Bereitstellungsmanifesten usw. pflegen. Diese dezentralisierte Konfiguration führt zu Folgendem:
- Konfigurationsdrift: Ohne eine einzige Quelle der Wahrheit ist es einfach, dass die Konfiguration in verschiedenen Umgebungen inkonsistent wird, da verschiedene Teams unabhängige Änderungen vornehmen.
- Mangel an Sichtbarkeit: Es gibt keine zentralisierte Möglichkeit, den gesamten Konfigurationsstatus über alle Dienste hinweg anzusehen, zu suchen und zu analysieren. Dies macht es extrem schwierig zu verstehen, wie ein Dienst konfiguriert ist.
- Audit-Herausforderungen: Änderungen an Umgebungsvariablen werden nicht auf eine standardisierte Weise verfolgt, was es schwierig macht zu überprüfen, wer was und wann geändert hat.
- Testschwierigkeiten: Ohne eine Möglichkeit, Konfigurationen einfach zu erfassen und zu teilen, wird es extrem mühsam, konsistente Umgebungen für Entwicklung und Tests sicherzustellen.
Anstatt dieses fragmentierten Ansatzes ermöglicht eine zentralisierte Konfigurationslösung es Teams, die Konfiguration von einer einzigen Plattform oder einem einzigen Repository aus zu verwalten.
Bauen Sie Ihre Apps mit Umgebungsvariablen für die Langzeit
Wenn Ihre Anwendung wächst, sollten Sie überlegen, wie Sie möglicherweise fortschrittlichere Methoden benötigen, um deren Konfigurationseinstellungen zu verwalten.
Was jetzt einfach erscheint, könnte später komplizierter werden. Sie werden wahrscheinlich bessere Möglichkeiten benötigen, um den Zugriff zu steuern, Team-Einstellungen zu teilen, alles klar zu organisieren und Konfigurationen reibungslos zu aktualisieren.
Malen Sie sich nicht in die Ecke, indem Sie von Anfang an nur Umgebungsvariablen verwenden. Sie sollten planen, wie Sie mit Konfigurationen umgehen, wenn Ihre Anforderungen steigen.
Während Umgebungsvariablen ideal sind, um umgebungsbezogene Daten wie Anmeldeinformationen, Datenbanknamen, lokale IPs usw. zu verwalten, möchten Sie ein System erstellen, das soliden Prinzipien wie Sicherheit, Teilbarkeit, Organisation und der Fähigkeit, sich schnell an Veränderungen anzupassen, folgt.
Die Alternativen, die wir besprochen haben, wie die Verwendung einer dedizierten Konfigurationsdatei oder eines Dienstes, haben wertvolle Funktionen, die mit diesen Prinzipien übereinstimmen. Das wird Ihnen helfen, schnell weiterzukommen, ohne verlangsamt zu werden.

